Computer Vision: The science and technology of machines that can see.
Chapter 1: An Introduction to the Project, Aims and Objectives
1.1 Introduction
Computer vision is the science and technology of machines that can see. As a scientific discipline, computer vision is concerned with the theory behind artificial systems that extract information from images. The image data can take many forms, such as video sequences, views from multiple cameras or multi-dimensional data from a medical scanner. In simple terminology it can be understood to be the ‘visual sense of a machine‘. The end-use of providing visual aid to a machine includes visual detection capabilities, enhancing interaction with the machine, enabling machines to model the environment and then taking the necessary actions. This can be deployed in robotic applications such as a robotic vision system.
Robotic vision can be viewed as that part of computer vision that is intended to guide the actions of robots. As stated by Ray Jarvis (2005), the quality of a robot vision system is judged in terms of whether it can provide timely, reliable and accurate real-time information. This information can be extracted from visual or range data (or both), and can be used to direct the correct action of a robot in carrying out a specified task. The range of the task depends on the extent that its structure permits its use over a wide range of possibilities.
The first step in the robotic vision process is the acquisition of an image; typically from cameras. This forms the basis of this project. The aim of this project is to build robotic vision software packages that can be grab images which can then be used as input for various digital image-processing techniques that are used to model the real-world around the robot. Typical techniques which can be used include blob extraction, pattern recognition, barcode reading, optical character recognition, gauging (measuring object dimensions) and edge detection. All of these enable the robot to understand its environment.
1.2 Background
The following project was part of the work package that Microsystems and the machine vision laboratory, Sheffield Hallam University (MMVL), intends to accomplish as a partner of the ongoing research at REPLICATOR Consortium. This is supported within three large-scale, integrated projects by the European Commission. Started in 2008, the Replicator refers to Robotic Evolutionary Self-Programming and Self-Assembling Organisms that are similar to swarm robots.
The main focus of the consortium is to investigate and develop principles of adaptation and co-operation of bio-inspired swarm robots that can dynamically aggregate into one or many symbiotic organisms and collectively interact with the physical world via a variety of sensors and actuators. Vision is an important sense for the Replicator system as it can provide very useful information on its interactions with the world. This information can range from simple directional information on locomotion to more complex object recognition and scene understanding. Vision, in general, is useful for gathering information about situations in the robot’s external environment so that it can take necessary actions such as obstacle avoidance and pattern recognition. It is important for the identification of other robots in the swarm and be part of collective movement towards a common destination.
Since the design of the camera module was part of the ongoing Replicator project, the selection of camera hardware and processor type was done in accordance with the Replicator robots. Similar types of hardware boards were constructed at the MMVL to resemble the actual hardware used in the robots. The final software deliverable was tested on single- and dual core processors that will be used in the Replicator robots. Further changes to the software may be needed to adapt to the changes made (if any) in the final implementation of the robots.
Although the development of the vision system was done as per the specifications stated by the Replicator project, the end product can be used in any image-grabbing application which uses a similar platform.
1.3 Importance and Relationship of the Work to Previous Work
Prior to the start of this project, the hardware was developed at the MMVL in accordance with the actual Replicator project. Also, some initial code was developed to grab images from OV7660 cameras using BF537 and extender boards. This project is a further enhancement of this work.
1.4 Aims and Objectives
The main aim of the project is to devise a camera module compatible with the different versions of the Blackfin processor that can be used for any embedded system application. The project can be summarised by the individual aims:
- To test and verify the existing hardware consisting of a BF537 processor and camera OV7660.
- Debug and resolve compilation issues and programme errors using Visual DSP++ environment.
- Devise chip enabler in hardware and software for the port expander IC and the camera module.
- Test and verify the new PCB designs with the existing software and hardware.
- Upgrade the system to include camera OV7670 and BF561 dual core processor. Make necessary changes in software for the same and test the complete configuration.
- Improve the quality of image received for the final configuration.
- Create device drivers for the final configuration that is capable of automatic camera detection and is compatible with single core and dual core processors.
1.5 Critical Literature Survey
The field of robotics has gained mass popularity in recent years. Many industrial bodies have tried to provide an exact definition of what robotics stands for, yet there is no definition that can fully encompass the complete essence of the vast possibilities that this field of technology holds for the future. In ISO 8373, the International Organization for Standardization (2010) defines a robot as ‘an automatically controlled, reprogrammable, multipurpose manipulator with three or more axes.’ The Robot Institute of America (2010) designates a robot as ‘a reprogrammable, multifunctional manipulator designed to move material, parts, tools, or specialized devices through various programmed motions for the performance of a variety of tasks.’ These definitions are mere indicators of the possibilities of what a robot can accomplish; there are far more functions then can be stated in a definition.
It is humans’ vivid imaginations that have inspired people to create artificial life. This appeal was first seen in motion pictures with the invention of Frankenstein, a story about the construction of a human-like creature, by Mary Shelly in 1818. This creature was created from nuts and bolts; it could function exactly like a human but with enhanced strength and capabilities. The word ‘robot’ was unknown until the famous play written by Karel Capek in 1920, Rossum’s Universal Robots, commonly known as R.U.R. The Czech word robotnik refers to a peasant or serf, while robota means drudgery or servitude. These words gradually became a part of the English language without much translation. While the concept of a robot has been around for a very long time, it was not until the 1940s, with the arrival of computers, that the modern-day robot was born.
Following World War II, America experienced a strong industrial push which caused rapid advancement in technology in sectors such as electronics, solid state devices, and digital electronics which helped the robotic industry to grow in leaps and bounds. During the late 1950s and early 1960s, robots became popular with the automotive industry where industrial robots were used to help factory operators. Although these robots did not have the human-like appearance as dreamt of throughout the ages, they did have computer-controlled manipulators, like arms and hands, marking the beginning of artificial help.
Robots were created mainly as human helpers; however, soon they were being deployed were in high risk and dangerous situations. They can now be used to deactivate a bomb, explore the edges of an active volcano, transport dangerous materials, and explore the ocean floor. They have even been deployed in places most hostile to humans; outer space expeditions. Without the proper protection, survival in space is not possible. When repairs have to be made outside a spacecraft, astronauts are sometimes required to leave the space shuttle or the space station. These extravehicular activities are very dangerous and, therefore, robots are used to carry out tasks in space in order to limit the risks.
Today, artificial intelligence has also become an important and integral part of the robotics industry. This means, given some basic training, robots make decisions based on their surroundings and adapt to them. Technology is fast moving towards the development of smart, adaptive robots that are capable of making decisions based on their surroundings and working in swarms or in co-operation with each other. This means that the robots need to be aware of their surroundings and obtain real-time information about the changing environment; this is very similar behavior to that of humans. This is where the robotic vision comes into the picture. An important aspect is making robots more human-like and efficient in performing the tasks on their own. Embedded computer vision is a relatively new concept. The vast popularity that embedded computer-vision systems have gained is because the component costs became low enough for them to be used in small, low-power systems. This was due to the increasing research in the field of semiconductor devices. Such systems help to add reliable movement and provide real-time information to the system. The use of such systems are evident in places such as detection in security cameras or face recognition in cell phones or digital cameras.
A lot of research and development has taken place and many papers have been written in the field of robot vision with algorithms for image processing and pattern recognition.
As stated in a recent paper (Loten, 2008) submitted to the IEEE, being a relatively new research area, embedded computer vision technology has little in the way of established frameworks or open libraries that are freely available. This could also be attributed to the large range of devices that would need to be supported in order for it to be successful, which would make optimisation rather difficult.
There are a number of factors that need to be kept in mind when developing an embedded system application for robotic vision. The common approach is to break the system down into smaller components or individual tasks that can be developed and tested and then recombined to make a completely integrated system. The components of the system are usually considered to be: processor boards that form the brain of the device, the vision system that forms the input, comprised of the camera module, and, finally, the output system that may be based on repositioning the robot by wheel rotation, pattern recognition, communicating the response to other robots etc. In each of these stages, the selection of components is a crucial task.
The first and foremost selection of components is that of the processor. As described in a recent paper (Kisacanin, 2005), designing an embedded, real-time, computer vision system is a complex task and involves multiple trade-offs, such as choosing a processor that will offer enough ‘horsepower’ to do the job in a timely manner, but will not cost a lot or consume too much power. Some major parameters that dominate the choice of processor selection are as follows:
- Fast memory: In order to avoid idle cycles due to read and write latency characteristics of external memory, it is advantageous to have fast, internal on-chip memory. This also reduces memory-size requirements as imaging functions have a high locality of reference for both data and the code.
- Wide data bus with Direct Memory Access (DMA): Image processing units tend to use up a large amount of memory. Since the amount of data that needs to be given to the processor is large, considerable width of data bus is needed. Having DMA architecture for the image transfers helps in faster access to the memory and increases the overall efficiency of the system.
- Parallelism: Stage pipelining becomes an important part of the image processing system since it helps in faster execution. Phases of instruction processing, commonly referred to as ‘Fetch’, ‘Decode’, ‘Execute’, and ‘Write’, when done by a parallel architecture, help to reduce the time for processing. Another approach to parallelism is instruction parallelism; the use of SIMD (Single Instruction Multiple Data) refers to multiple identical processing units operating under control of a single instruction, each working on different input data. The issue of parallelism is achieved using superscalar architectures.
In general, computer vision involves the processing of images. Image processing is an extreme case of digital signal processing since it requires fast memory, wide data busses with DMA, and processor parallelism. In this project, an embedded computer vision framework on Analogue Devices Blackfin processors was done. Initially, single core BF537 was used but, later, a BF561 device, which was chosen due to its large cache size, multiple video streaming capability and symmetric dual core design was used. These processors belong to the ADSP family that is specially designed to handle digital signal processes and thus they form an obvious choice in processor selection. Blackfin devices have a wide range of on-chip peripherals, including DMA and a parallel peripheral interface (PPI) which can be used to provide uninterrupted transfer of data from memory to external devices such as video encoders, with no processing overhead.
The next important parameter to be chosen is the camera module. There are a number of factors that affect the choice of camera module such as the resolution needed, cost, format specification, compression ratio, power dissipation and frame rate. There are a variety of cameras available on the market today. They are divided into two main categories, based on the technology used; CCD and CMOS. A major advantage of CMOS versus CCD camera technology is the ability to integrate additional circuitry on the same die as the sensor itself. This makes it possible to integrate the analogue to digital converters and associated pixel-grabbing circuitry without the need for a separate frame grabber. There are a number of companies that provide CMOS cameras such as Omnivision technologies, Aptina, Atmel, Micron, Neuricam, Pixelplus, Sharp etc. The main aim is to select a camera module that provides the correct resolution with efficiency and with minimum time delay. Also, compatibility with the processor is very important in camera selection. The camera should be easily reconfigurable with minimum interface needed for the communication to take place. As stated in a recent paper (ROWE, 2002), the OVxx series of cameras provided by Omnivision Technologies are CMOS VGA (video graphics array) cameras that can be easily mounted and interfaced with processors. They can communicate with a simple, three-wired or two-wired SCCB interface that resembles the standard I2C interface for communication between processor and peripheral devices. Also, the camera parameters such as colour saturation, brightness, contrast, white balance, exposure time, gain and output modes are programmable. Thus the camera can be reconfigured as per choice.
In recent years, there has been a lot of development in algorithms for the grabbing of images. These have been evaluated on the basis of speed, bus width and its effective use, and the format used to grab the image. The choice of algorithms forms a common trade-off. On the one hand, they have to be robust and flexible while, on the other hand, they have to run in real-time on the selected platform. The proper settings of DMA and PPI registers need to be done in order to grab the image in different modes. Image-grabbing can be in single-shot mode or multi-shot mode. This depends on the number of times the camera’s sensor is exposed to light. In multi-shot, the sensor is exposed to the image in a sequence of three or more openings of the lens aperture. This technique uses a series of single shots and stitches them together in order to achieve a panoramic view of the surroundings. Another important setting that needs to be considered is whether to capture the image using ITU-656 standards or without any standards. These techniques will be discussed in more detail in subsequent chapters.
Chapter 2: Theory and Related work 2.1 Introduction
Image capture forms an important part of this project as real-time images are captured and processed. This chapter explains the related theory about image capture such as the sensor array, the image file formats and type of camera used. The series of cameras used has also been explained in this chapter. Real-time images are captured in order to specify the current state of the surroundings for the robot. As explained in this chapter, the code was developed and tested for two series of Omnivision Cameras; OV7660 and OV7670. These two cameras are similar in operation but have minor differences in parameter configuration and expansion of the sensor array. The camera is connected to the main processor via the SCCB interface whereas the image transfer takes place via the PPI interface. The hardware description is given in Chapter 3, section 3.3.2.
2.2 VGA (video graphics array) Cameras
VGA is a computing standard and usually refers to a resolution of 640×480 machines originally developed by IBM. VGA cameras are an old version of the camera but are still used widely in some applications such as mobiles and surveillance cameras. They compute to around 0.3 megapixels and therefore, compared to a standard 10 megapixels camera, they have less resolution.
This conversion is computed as follows:
307200/1000000 = 0.3 megapixels (approximately)
So a VGA camera is, in fact, a 0.3 megapixels camera. The Omnivision camera series used in this project is a VGA type of camera.
Other formats of VGA are shown in the table below:
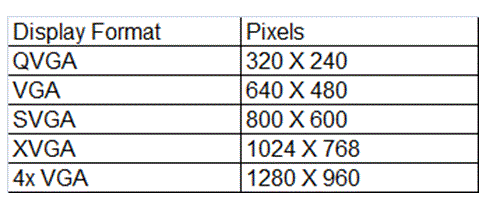
Figure 1: Display formats
2.3 Types of Camera Sensor Array
The camera consists of an image sensor made up of a number of pixels or picture elements that define its resolution. To capture an image, the camera aperture is exposed to light, which then passes through the lens and falls onto the image sensor. The pixels in the image sensor convert the received amount of light into a corresponding number of electrons. The stronger the light, the more electrons are generated. The electrons are converted into voltage and then transformed into numbers by means of an A/D-converter. The signal constituted by the numbers is processed by electronic circuits inside the camera.
The two main technologies that can be used for the image sensor in a camera are CCD (Charge-coupled Device) and CMOS (Complementary Metal-oxide Semiconductor). Figure 1 shows CCD and CMOS image sensors.

Source: LUKAC (2009)
Figure 1: Image Sensor arrays, CCD (left) and CMOS (right)
CCD is an older version of camera technology and, these days, most of the cameras incorporate the CMOS technology. CMOS cameras come with enhanced light sensitivity and an incorporated amplifier and A/D converters. This lowers the cost of the camera since extra modules are not needed and, therefore, the functionality increases.
CMOS sensors also have a faster readout, lower power consumption, higher noise immunity, and a smaller system size. It is much easier to calibrate a CMOS array and most cameras these days incorporate a self-calibrating capability. It is possible to read individual pixels from a CMOS sensor, which allows ‘windowing’. This implies that certain parts of the sensor area can be read instead of the entire sensor area being read at once. In this way, a higher frame rate can be delivered from a limited part of the sensor, and digital PTZ (pan/tilt/zoom) functions can be used. However, this addition of circuitry inside the chip can lead to a risk of more structured noise, such as stripes and other patterns.
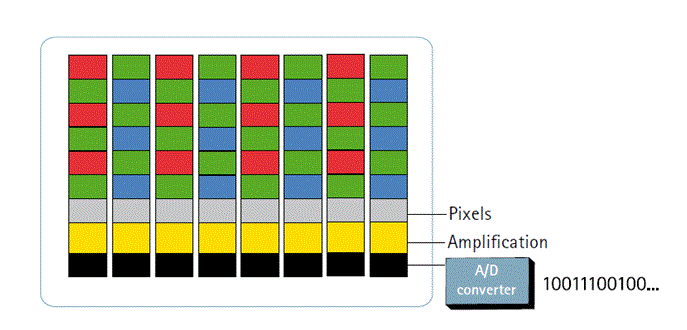
Source: LUKAC (2009)
Figure 2: Image CMOS Sensor array layout
The Omnivision camera series used in this project is a CMOS type of camera.
2.4 Colour Filtering
The sensor array mentioned above is used to capture the amount of light that falls on it, thus it does not have the capability to interpret colours. Colour filters are used in order to provide actual colours to the image captured by the sensor array. There are two main methods of colour filtering; RGB and CMYG.
RGB refers to red, green and blue, which are also the three receptors of the human eye. Human vision interprets colours by translating light into one or more wavelengths. When the wavelength of light changes, the colour changes. All the colours that humans can perceive are a combination of these basic colours. The cameras are made to replicate the human vision. Since CMOS and CCD image sensors are ‘colour blind’, a filter in front of the sensor allows the sensor to assign colour tones to each pixel. For example, a pixel with a red filter will record the red light while blocking all other colours.

Source: LUKAC (2009)
Figure 3: Bayer Array Image Sensor
The Bayer array, which has alternating rows of red-green and green-blue filters, is the most common RGB colour filter. Since the human eye is more sensitive to green than to the other two colours, the Bayer array has twice as many green colour filters. This also means that, with the Bayer array, the human eye can detect more detail than if the three colours were used in equal measures in the filter. In addition, the display of finer details can be accomplished if there are more green pixels producing an image than if each of the three colours were equally applied. The figure below represents the transmission pattern of the Bayer Array. As can be seen, different colours have specific wavelengths and are transmitted, without exception, in that wavelength band.
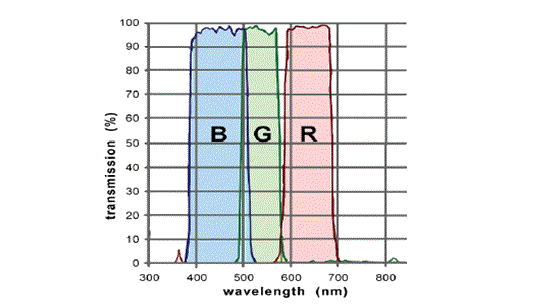
Source: PLANETERIUM (2008)
Figure 4: Transmission of the RGB-CCD-filters
Another way to filter or register colour is to use the complementary colours; cyan, magenta, and yellow. Complementary colour filters on sensors are often combined with green filters to form a CMYG colour array, as shown in Figure 5. The CMYG system generally offers higher pixel signals due to its broader spectral band pass. However, the signals must then be converted to RGB since this is used in the final image, and the conversion implies more processing and added noise. The result is that the initial gain in signal-to-noise is reduced, and the CMYG system is often not as good at presenting colours accurately.

Source: LUKAC (2009)
Figure 5: CMYG Array Image Sensor
The CMYG colour array is often used in interlaced CCD image sensors, whereas the RGB system is primarily used in progressive scan image sensors.
In this project, the raw image captured by the camera is converted into RGB format.
2.5 Image Formats and Compression Techniques
Standard image file formats provide interoperability between different file types. It ensures that photos taken from digital cameras of different types can be read and stored in computers and other digital storage devices.
The other reason to have standard file formats is for image compression and storage. Images can be thought of as surface graphs with x, y and z coordinates. The x and y correspond to the size of the image and also represent the resolution, whereas the z coordinate represents the depth or the intensity of light. Thus, the image’s intensity data is represented by its depth, which is the range of intensities that can be represented per pixel. For a bit depth of x, the image is said to have a depth of 2 ^x, meaning that each pixel can have an intensity value of 2^ x levels.
The memory required to store this image resolution is governed by the following equation
Source: RELF (2003)
Thus, as resolution increases, the memory requirements also increase. This is why there is the need to implement certain compression techniques to store the image. Compression is the process by which the image size is reduced to a form that minimises the space required for storage and the bandwidth required for transmission.
Compression can be either lossyor lossless. Lossless compression routines scan the input image and calculate a more efficient method of storing the image. This does not cause any loss in the information of data and thus the image remains the same. Lossy compression techniques tend to discard certain parts of the data according to a certain set of rules. This may cause loss of data and ultimately degradation of the image.
The following are the different types of image compression techniques:
2.5.1 JPEG
JPEG refers to the Joint Photographic Experts Group. Standard consumer digital cameras store images using the industry standard: Exif compressed image format, which uses the JPEG image compression standard. This enables the images from digital cameras to be used by many other devices, such as home computers, appliance printers, retail kiosks, and on-line printing services. The image files can be used by many different software applications and posted on web pages or emailed so that they can be accessed anywhere in the world. The JPEG compression technique analyses images, removes data that is difficult for the human eye to distinguish, and stores the resulting data as a 24-bit colour image.
The compatibility provided by the Exif-JPEG format has some drawbacks. The format uses baseline JPEG compression, which is limited to storing 24-bit colour images, using 8 bits per component for the luminance (Y) component, and the two colour components, red minus luminance (Cr), and blue minus luminance (Cb). This is of the lossy compression method and, thus, may not always be the right choice; typically when a higher quality of image is needed. In most cases, it is used as the standard compression technique.
2.5.2 TIFF (Tagged Image File Format)
TIFF files are very flexible, as the routine used to compress the image file is stored within the file itself. Although this suggests that TIFF files can undergo lossy compression, most applications that use the format use only lossless algorithms.
2.5.3 GIF
GIF (CompuServe Graphics Interchange File) images use a similar compression algorithm to that used within TIFF images, but the bytes and string table are reversed. All GIF files have a colour palette. Compression using the GIF format creates a colour table of 256 colours; therefore, if the image has fewer than 256 colours, GIF can render the image exactly. If the image contains more than 256 colours, the GIF algorithm approximates the colours in the image with the limited palette of 256 colours available. Instead of representing each pixel’s intensity discreetly, a formula is generated that takes up much less space.
2.5.4 PNG
The Portable Network Graphics file format is also a lossless storage format that analyses patterns within the image to compress the file. PNG is an excellent replacement for GIF images and, unlike GIF, is patent-free. PNG images can be indexed colour, true colour or gray scale, with colour depths from 1 to 16 bits. They can support progressive display, so they are particularly suited to Web pages. Therefore, most cameras provide a raw image format setting, which stores data that is directly related to the sensor colour information obtained from the sensor array.
2.5.5 BMP
Bitmaps come in two varieties, OS/2 and Windows, although the latter is by far the most popular. BMP files are uncompressed, support both 8-bit gray scale and colour, and can store calibration information about the physical size of the image along with the intensity data.
2.5.6 Raw image type
Raw image is the image that is received directly from the camera module, without being compressed by any compression techniques or algorithms. Since the raw-image file stores the data directly from the sensor, the characteristics of the raw-image data, such as the colour it encodes and the type of noise it includes, are specific to the type of digital camera that created the file. In order to produce the finished image, the host device must be able to perform the image processing required for the specific camera. The host device contains a set of algorithms to interpret the raw information and convert it into a meaningful image that can be displayed in any of the standard formats.
2.6 ITU-R 656 standards
‘ITU-R 656’ stands for ‘International Telecommunications Union – Recommendation standard 656’. It is formally known as CCIR 601 and is an international standard used for the transmission of images and video frames. It specifies a synchronous interface that includes an 8-bit video data and 27 MHz data clock. The protocol states the video timing signals such vertical and horizontal blanking encoded in the data stream. This is done by having the timing information byte precede the following 3-byte sequence {0xFF, 0x00, 0x00}. This 4-byte header and footer is called ‘start of active video’ (SAV) and ‘end of active video’ (EAV) and allows the interface to remove the need for separate vertical and horizontal sync signals, as they are encoded into both SAV and EAV headers.
EAV- End of Active Video: This is the start of the subsequent line and also marks the active video data within the current line. EAV begins with one code word in which all bits are set to one, whereas all the bits which are followed by two words are set to zero.
SAV-Start of Active Video: In a component digital video, a synchronising signal needs to be used. The start and the end of the active video signal is marked by a code SAV within the data stream. SAV begins with one code word in which all bits are set to one, followed by two words in which all bits are set to zero
EAV AND SAV codes are embedded within the BT.656 video data stream. They are comprised of a sequence of four bytes.
BLANKING: In between the two codes EAV and SAV, there is a horizontal blanking interval which is not related to video signal. This means it does not contain the sync pulse. During the horizontal blanking interval, between EAV and SAV codes, ancillary data can be inserted into the data stream. During vertical blanking intervals ancillary data can also be transmitted at any time.