Cloud Computing
Number of words: 33437
CHAPTER-1
INTRODUCTION
1.1 Cloud Computing
Cloud computing is a paradigm for providing on-demand for the network that is computable and also for the resources such as networks, servers, storage, applications, and services, which can quickly made available and launched with the minimized efforts of management or communication from service providers. The cloud environment is made up of five fundamental characteristics, three models of service, and four modes of deployment [1]. The topology of this cloud can be depicted as in the Fig 1.1 [2].
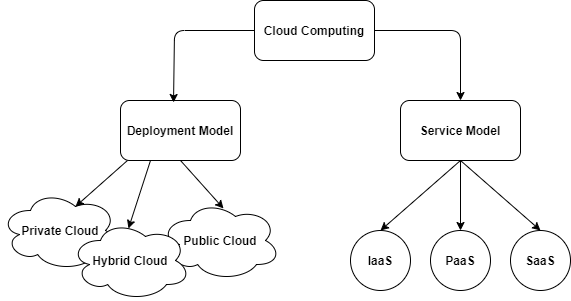
Fig 1.1 Cloud Computing
1.1.1 Deployment Models
Clouds come in a number of different forms, each one distinct from the others. Those are listed as below:
- Public Cloud: Anyone who wishes to use the cloud platform can do so. It might be taken, maintained, and opened up as a commercial, educational, or government institution, or a combination of these. It’s on the premises of the cloud provider.
- Private Cloud: Such platform is developed for a single entity with numerous users to use it specifically such as multiple units of business. It might be owned, administered, and directed by the company, outside business party, or a mix of the two and which can be on the site or also on the offsite areas.
- Hybrid Cloud: The cloud environment is made up of two or many separate cloud environments (private, communal, or public) that are making its operations on independent basis but are also have a link with a reliable or patented technology that allows data and application mobility (For example, cloud breaking for cloud load balancing). Due of the possibility for uniqueness in cloud scenarios and the distribution of management duties between the private organizations that are providing cloud and the providers of public cloud, hybrid models are regarded complicated and difficult to establish and maintain [3].
- Community Cloud: The community cloud is only available to a restricted set of clients from companies that share these concerns (e.g., mission, security needs, policy, and compliance issues). It might be taken, manageable or controllable by single or multiple community businesses, a third party, or a combination of the three, and it could occur on or off-site. [1].
1.2.1 Cloud Computing Services
IaaS (Infrastructure-as-a-Service), PaaS (Platform-as-a-Service), and SaaS (Software-as-a-Service) are the three most common cloud service categories (Software-as-a-Service).
- SaaS (Software-as-a-Service): The consumer has the option of utilizing cloud-based applications from the supplier. Through a variety of customer devices, applications may be accessible through a thin customer interface like an internet browser or a program interface. The client has no control or management over except for limited client explicit application settings, the hidden cloud foundation incorporates network, workers, working frameworks, stockpiling, and surprisingly specific capacities of the business in it.
- PaaS (Platform-as-a-Service): Customers or customers will be able to install consumer-built or purchased apps created on the cloud platform using the programming languages, libraries, services and tools. Consumers have no influence over the cloud infrastructure underpinning them, such as the network, servers, operating systems or storage, but manage the installed applications and perhaps the application-hosting setup settings.
- IaaS (Infrastructure-as-a-Service): For the construction and operation of arbitrary software, the client has the capacity to offer processing, storage, networks, and other essential computer resources, such as operating systems and applications. Customers have limited control over specific network components and do not manage or control the fundamental cloud infrastructure. They do, however, have control over operating systems, storage, and installed apps. (e.g. host firewalls) [1].
Virtual hosts can distribute resources across numerous guests or Virtual Machines with the aid of Virtual Machines in Cloud Computing.
1.2 Virtual Machine
A virtual machine (VM) is a virtualized computer. Virtual machine software can be used for running the programs and operational business movement, data storage, network and its connectivity, and do other activities, but it has to be updated on a regular basis and monitored. A single physical device, generally a server, can host several virtual machines that are managed by virtual machine software.
This allows computing resources (compute, storage, and network) to be allocated among these as required, resulting in increased overall performance.
1.2.1 Advantages of Virtual Machine
Virtual machines are simple to operate and maintain, and they provide a number of benefits over physical or real machines:
- “Virtual machines may run several operating systems one device, conserving the space, time, and additional expenditure to be incurred”.
- “Virtual machines let older programs run more smoothly, decrease in the expenditure of heading to the other OS”. From Linux, the operations can be headed to windows operations.
- The other operational usage of this can be the recovery from disasters and application availability.
1.2.2 Types of Virtual Machines
These are categorized into two categories: process VMs and system VMs:
- Process virtual machine: A process virtual machine hides the specifics of the underlying hardware or operating system, allowing a single host to be a single operational process for operations, offering the independent platform of development. A process VM is something like the Java Virtual Machine, which lets any OS for running its applications similar to a way as they are related to this OS or machine.
- System virtual machine:A system that is entirely virtualized A virtual machine can function in the same way as a real machine. A system platform enables several virtual machines to share the physical resources of a host computer while each operating their copy of all the OS. A hypervisor, which may run on bare hardware like VMware ESXi or ranking the position of the OS, manages this virtualization approach.
1.2.3 Cloud security challenges for virtual machines
Cloud computing security, often known as cloud security, is a collection of rules and technology that safeguard the cloud computing system’s services and resources. Cloud security is a subdomain of cyber security that covers methods for protecting cloud computing systems’ services, applications, data, virtualized IP, and related infrastructure.
Virtualized environments including virtual machines (VMs) and containers are present unique risks to cloud security. The cloud security issues posed by virtual machines can include performance problems, hardware expenses, semantic gaps, malicious software, and overall VM system security.
- Performance:
The cloud security services running on the system, hurts the VM system performance. This is due to the overhead of virtualization and inter-VM communication. Device access take up the required aspects and results exchange via cross-VM communication require extra costs of switching, which results in the increased OH of the systems.
- Hardware cost:
To ensure complete security of the virtual machines requires an efficient deal of attached resources with it. Further, using older resources or limited memory might not make the operations of the system to work systematically.
- Semantic gaps:
A problem to VM security is the semantic mismatch between the guest operating system and the underlying virtual machine monitor (VMM). Security services often require processing time to reason about a higher level of guest VM state, whereas the VMM can monitor the raw status of the guest VM.
- Malicious software:
Malicious software is another challenge for VM security. That said, VMs can be used to thwart these attacks, too. For example, various techniques are available for VM fingerprinting that can act as a honeypot for malware, such as the Agobot family of worms.
- System security:
Feature updates to cloud security services can inadvertently introduce backdoor vulnerabilities into the VM, which can then be exploited to gain access to the infrastructure as a whole.
1.2.4 Steps to protect virtualized environment
Step1: Actively monitor and update the security system
Actively monitor and analyze the hypervisor for any potential signs of compromise, and continuously audit and monitor all virtual activities. The systems must be up-to-date effective issues are made of the security system. Be sure to use the most recent hypervisor, and promptly making the application of maintenance of applications.
Step2: Implement access controls
Strong firewall controls the system and its confidentiality for making an access that is not authorized to maintain its confidentiality. Provide limited access for users to prevent modification to the hypervisor environment. Enforce strict access control and multi-factor authentication for any admin function on the hypervisor.
Step3: Separate and secure the management
To reduce the risk of VM traffic contamination, the management infrastructure should be physically separate. Above all, secure the management and VM data networks.
Step4: Use a hypervisor and disable unnecessary services
The hypervisor host management interface should be placed in a dedicated virtual network segment, only allowing access from designated subnets in the enterprise network. Guest service accounts or sessions that are not necessary should be deactivated. Disable unneeded services, such as clipboard or file sharing.
Step5: Use translation techniques and SSL Encryption
Always use network address translation techniques and Secure Sockets Layer (SSL) encryption in communication with virtual server command systems.
By spreading traffic over several network servers, a Virtual Load Balancer gives you more flexibility in balancing a server’s burden. Through virtualization, virtual load balancing attempts to imitate software-driven infrastructure. On a virtual computer, it executes the software of a physical or real load balancing device.
1.3 Load Balancing
The process of dividing workloads and computational resources in a cloud computing environment is commonly known with the name of cloud load balancing. The workloads of the business can be managed by making active resource distribution on the servers and networks. Fig 1.2 [4] show the simple load balancing process.
The following are some of the most prevalent reasons for using load balancers:
- To keep the system stable.
- To boost the system’s efficiency.
- To avoid system breakdowns.
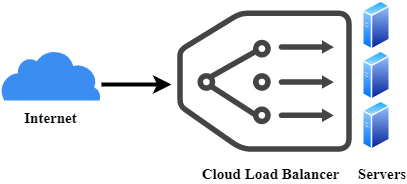
Fig 1.2 Load Balancing
1.3.1 Advantages of Cloud Load Balancing
The advantage of load balancing is listed as below:
- High Performing applications: Unlike their on-premise counterparts, cloud load balancing solutions are less costly and easier to implement. Client apps may be made to run quicker and offer better results, all while potentially saving money.
- Increased scalability: To manage website traffic, cloud balancing makes use of the cloud’s scalability and agility. You can quickly match up increasing user traffic and spread it among multiple servers or network devices by utilizing effective load balancers. It is particularly essential for ecommerce websites, which deal with thousands of users per second. They require such efficient load balancers to disperse workloads during sales or other special offers.
- Business continuity with complete flexibility: The primary aim of this balancer is to protect or save the web page from unexpected outages. At the operations when, a job is distributed over many units of servers, the task may be moved to another active node if one node fails.
1.3.2 Challenges in cloud-based load balancing
The challenges are mentioned follow:
- Virtual machine migration (time and security): Because cloud computing is a service-on-demand model, resources should be available when a service is needed. Moving resources (often virtual machines) from single server to the other servers, sometimes from a long distance, is required. In such situations, load balancing designer algorithms must look at two issues: migration time, which impacts performance and likelihood of assaults (security issue).
- “Spatially distributed nodes in a cloud: Cloud computing nodes are globally dispersed. In this instance, the difficulty is to develop load balancing algorithms to account factors such as network bandwidth, communication rates, distances between nodes and the distance between customer and resources”.
- “Single point of failure: When the node running the algorithm controller fails, this single point of failure causes the entire system to crash. The problem is to develop algorithms with distribution or decentralization.
- Algorithm complexity: The implications and the operations shall be controlled using this in the business operations. If the algorithms are complex then all these can have the negative impact over the entire operational aspects performed.
- Emergence of small data centers in cloud computing: small data centers have lesser values and use less energy than big data centres. Computing resources are thus spread worldwide. The difficulty here is to develop algorithms that balance loads for an acceptable reaction time”.
- Energy management: Algorithms for load balancing should be developed to reduce energy usage. Therefore, they should follow the approach for energy-aware planning tasks.
To perform a process and maintain a resource in a cloud computing environment, a good load balancing approach is necessary. They generate a decent schedule based on the present status of the cloud resources and do not account for resource availability changes.
1.4 Scheduling Approaches
The act of mapping a collection of workloads to a group of virtual machines (VMs) or assigning VMs to operate on available resources in order to satisfy the demands of users is referred to as scheduling in cloud computing.
Inefficient scheduling algorithms struggle with resource excess and underuse (imbalance), leading in service degradation (in the case of overuse) or cloud resource waste (in the case of underuse) (in the case of underuse).
The fundamental idea behind scheduling is to distribute workloads (of various and complex types) across cloud resources in such a way that the process does not result in an imbalance. The scheduling algorithm should maximize response time, dependability, availability, energy consumption, cost, resource utilization, and other key performance indicator parameters. [5].
1.4.1 Scheduling Levels
There are two layers of scheduling techniques in the cloud environment:
- First level: a collection of policies for distributing VMs in a host at the host level.
- Second level: at the VM level, a collection of policies for assigning tasks to VMs.
1.4.2 Benefits of Scheduling algorithms
- Control the performance and quality of service of cloud computing.
- Manage the processor and the memory.
- The optimal scheduling algorithms make the best use of resources while reducing the total job execution time.
- Enhancing the level of fairness in all tasks.
- Increase the amount of tasks that have been completed successfully.
- Achieving a high system throughput.
- Improving load balance.
1.4.3 Task scheduling algorithms classification
Static and dynamic scheduling algorithms are the two types of scheduling algorithms. Static scheduling has a lower runtime overhead since it requires previous obtaining of needed data and pipelining of distinct task execution stages, whereas dynamic scheduling requires no prior knowledge of the job/task. As a result, the job’s execution duration is unknown, and task assignment is done as soon as the program runs [6, 7].
- Static scheduling: In comparison to dynamic scheduling, static scheduling is regarded to be relatively easy since it is dependent on prior knowledge of the system’s global state. It ignores the present state of VMs and splits all traffic equally across all VMs in the same way as round robin (RR) and random scheduling methods do.
The characteristics of static algorithms are:
- They decide based on a fixed rule, for example, input load
- They are not flexible
- They need prior knowledge about the system.
- Dynamic scheduling: Considers the present state of virtual machines without requiring prior knowledge of the system’s overall status, and distributes work based on the capability of all available virtual machines [8].
Nearly all Dynamic algorithms follow four steps:
- “Load monitoring: In this step, the load and the state of the resources are monitored
- Synchronization: In this step, the load and state information is exchanged.
- Rebalancing Criteria: It is necessary to calculate a new work distribution and then make load-balancing decisions based on this new calculation.
- Task Migration: In this step, the actual movement of the data occurs. When system decides to transfer a task or process, this step will run.
The characteristics of dynamic algorithms are:
- They decide based on the current state of the system
- They are flexible
- They improve the performance of the system”
1.4.4 Types of scheduling algorithms
- Resource Aware Scheduling Algorithm: RASA is a hybrid scheduling strategy that incorporates both the Min-min and Max-min methods. The Min-Min technique is used to finish small tasks before moving on to larger activities, whereas the Max-Min method is used to eliminate delays in big task execution. The results are exchanged in the sequential execution of a small and a big job on different resources, ignoring the waiting time of small tasks in Max-min calculations and the waiting time of large assignments in Min-min calculations. [9].
- Priority scheduling algorithm: Priority scheduling is a pre-emptive method that allows each task in the system to execute depending on its priority.”The job with the greatest priority can run first, while the job with the lowest priority can be put on hold.”FCFS order is used to schedule Equal-Priority tasks. This method has one disadvantage: it starves a process [10].
- Max-Min scheduling Algorithm: The Max-min algorithm is quite similar to the Min-min method in terms of how it works. The distinguishing characteristic is that the word minimum is substituted by maximum, and the job with the earliest completion time is assigned to the associated resource. Larger jobs are prioritized than lesser jobs [11].
- Honey bee scheduling: This algorithm, similar to ACO and it is motivated by social agents and mimics honey bee foraging behavior to discover the best feasible solution. The flower patches, which have more nectar and pollen, are the food source here. Scout bees are a kind of bee that forages for food. They return to the hive after successfully locating the food source and begin to dance. The primary motivation for this action is to raise awareness of the food’s quality and quantity, as well as its location. In a beehive community, Forager honey bees take the Scout Bees to the food source and then begin collecting it. They then return to the hive and waggle their way to other basic honey bees in the hive, giving a consideration to the food that has been left. This leads to a further study of the path [12].
It may be used to solve both combinational and computing problems, and it can produce both generic and optimum solutions. Its goal is to distribute workloads among resources in the most efficient way possible in order to minimize overall execution time, lower execution costs, and increase cloud service performance [13].
While scheduling task to a virtual machine there is a lot of possible risk can occurred. To avoid such a problem effective risk management process is required. The primary component of success throughout the project’s execution is having a risk management plan that may assist decrease risk. Furthermore, employing an effective risk analysis approach aids risk management in obtaining a precise result that aids in making the best solution possible to prevent the risk.
1.5 Risk Management
Risk management became one of the cloud platform controls that aim to analyze and manage cloud computing risks in order to avoid them having an impact. Some high level risks are listed as below:
- Business case – The advantages and cost reductions may be exaggerated, because they do not take into account ongoing hazards and operational expenses.
- Data ownership – There’s a lot of confusion regarding who owns the data on the cloud (for example trade secrets, intellectual property, and customer details).
- Data security – Failure to implement business security standards in the cloud provider’s infrastructure and have faith in the cloud’s security safeguards.
- Sovereignty – There is a lack of information as to which nation and legal authority owns the data in the cloud.
- Assurance – Inability to get enough confidence on controls inside the cloud provider’s infrastructure.
Compliance issues, identity theft, malware infections and data leaks, diminished consumer confidence, and significant income loss are the primary security concerns of cloud computing.
1.5.1 Cloud Security Risks
Loss of Data: Natural disasters, criminal acts, or data wipes by the service provider can all result in the loss of data stored in cloud servers. Losing secret information may be disastrous for businesses, especially if they don’t have a backup strategy in place. One of the real time examples is Google. After being struck by lightning four times in its power supply cables, Google is one of the large digital companies that has lost all of its data permanently.
Malware Attacks: Cloud services may be used to steal private data. As technology advances and security measures improve, cybercriminals develop innovative methods for delivering malware to their intended targets. Attackers encrypt sensitive information and post it to YouTube as video files.
Diminished customer trust: Customers would undoubtedly feel insecure as a result of your company’s data breach issues. Millions of consumer credit and debit card details were stolen from information storage areas as a result of huge security flaws. Customers’ faith in the security of their personal information has been eroded as a result of the breaches. A data breach will undoubtedly result in a loss of clients, which will have an influence on the company’s income.
1.5.2 Managing Cloud Security
To successfully limit the security dangers posed by unmanaged cloud usage, businesses must analyze the data that is being moved to cloud servers and who is submitting the data. The processes outlined below will help corporate decision-makers and business IT managers analyze the security of their company’s data in the cloud.
Enforcing privacy Policies: Personal and sensitive data privacy and security are critical to any company’s success. Personal data kept by a corporation might be exposed due to bugs or security failures. If a cloud service provider fails to offer adequate security, the firm may consider moving cloud service providers or not keeping critical data in the cloud.
Cloud networks security: Malicious traffic should be identified and stopped during evaluations of cloud networks. Cloud service providers, on the other hand, have no idea of knowing what network traffic their customers intend to transmit and receive. After that, organizations and their service suppliers must collaborate to develop safety precautions.
Assess security vulnerabilities for cloud applications: Various kinds of data are stored on the cloud by different organizations. Depending on the type of information the company wants to protect, different aspects should be taken. Both the supplier or provider and the company face a variety of problems when it comes to cloud application safety. There are distinct concerns for both parties based on the cloud service provider’s deployment type, such as IaaS, SaaS, or PaaS.
Ensure governance and compliance is effective: To secure their assets, the number of businesses has already created privacy and compliance strategies or policies. They should also develop a governance framework that provides authority and a chain of duty inside the company, in addition to these policies. The responsibility and duties of each employee are clearly specified by a well-defined set of policies. It should also specify how they communicate and exchange data.
Service Level Agreement (SLA) breakdowns are a key concern or risk in cloud computing when utilizing cloud services. The SLA in terms of risk management is one of the topics that haven’t gotten much attention in cloud security.
1.6 SLA Violation Handling
A Service Level Agreement (SLA) is a contract among a cloud service provider and a customer that guarantees a certain level of performance.
SLA is formed at several levels, as shown below:
- Customer-based SLA: This kind of contract is utilized by individual clients and includes all the essential services that a customer may need while only utilizing one contract. It provides information about the kind and level of service accepted. For example, phone calls, messages and Internet services come under a telecommunications service, yet all of them are covered in a separate contract.
- Service-based SLA: This SLA is a contract with a same service type for all of its customers. Since the service is confined to one unchanging standard, it is easier and easier for suppliers. For example, adopting a service-based IT Helpdesk agreement would imply that the same service applies to all end-users that sign the service-based SLA.
- Multilevel SLA: This agreement is tailored to the requirements of the end user. In order to provide a more convenient service, the user integrates a number of criteria into the same system. The following sub-categories may be classified into this kind of SLA:
- Corporate level:This SLA requires no regular changes since its problems are usually unchanged. It contains an extensive explanation of all the essential elements of the agreement and applies to all end-user customers.
- Customer level:This contract addresses all service problems related to a certain client group. However, the kind of user services is not taken into account. For example, if a company asks for a stronger degree of security in one of its divisions. In this scenario, the whole business is protected by a security agency but, for particular reasons, needs a customer to be safer.
- Service level:In this agreement, all aspects attributed to a particular service regarding a customer group are included.
Only some SLA is actionable as contracts; the majority is agreements or contracts that are more akin to an Operating Level Agreement (OLA) and may not be subject to legal restrictions. Before signing a big deal with a cloud service provider, it’s essential to have an attorney check the agreements. The following are some of the parameters that are commonly specified in SLA:
- Availability of the Service
- Response time or Latency
- Each party accountability
- Warranties
1.6.1 Two major Service Level Agreements
Microsoft makes the SLA associated with the Windows Azure Platform components available, which is standard practice among cloud service providers. There is separate SLA for each component. The following are two important SLA:
- Windows Azure SLA- SLAs for computing and storage in Windows Azure are different. For computing, when a customer runs two or more role cases in distinct fault and upgrade domains, the client’s internet facing roles are guaranteed to have external connection at least 99.95 percent of the time. Furthermore, all of the customer’s role cases are analyzed, and errors in a role case’s process are guaranteed to be detected 99.9% of the time.
- SQL Azure SLA- SQL The database and internet gateway of SQL Azure will be accessible to Azure customers. Within a month, SQL Azure will be able to handle 99.9% Monthly Availability. Availability for a month, the percentage of the time the database was accessible to consumers to the entire time in a month is the proportion for a certain tenant database. In a 30-day monthly period, time is measured in minute intervals. Availability is always paid for a full month. If the customer’s efforts to access to a database are refused by the SQL Azure gateway, this period of time is reported as unavailable.
The use model is the foundation for SLA. Cloud companies frequently charge a premium for pay-per-use resources and only utilize conventional SLAs for that purpose. Customers can also pay at various levels that ensuring access to a set number of bought resources. Many times, the SLAs that come with subscriptions include a variety of terms & conditions. When a customer wants access to a certain amount of resources, he or she must subscribe to a service.
1.6.2 SLA setup criteria
A list of key criteria must be created in order to consistently construct a successful SLA.
- “Availability (e.g. 99.99% during work days, 99.9% for nights/weekends)
- Performance (e.g. maximum response times)
- Security of the data (e.g. encrypting all collected and transferred data)
- Disaster Recovery expectations (e.g. worse case recovery commitment)
- Location of the data (e.g. consistent with local legislation)
- Data accessibility (e.g. data retrievable from provider in readable format)
- Portability of the data (e.g. ability to transfer data to a distinct provider)
- The procedure for identifying problems and the timeline for resolving them (e.g. call center)
- Change Management process (e.g. changes – updates or new services)
- Dispute mediation process (e.g. escalation process, consequences)
- Exit strategy with provider expectations to enable a seamless transition”.
1.6.3 Benefits of the SLA
Some of the benefits of the service level agreement are discussed as below:
- Protects both parties. If internal IT delivers a new framework, they collaborate closely with end users to ensure that everything is functioning properly. They use emails and phone calls to follow framework success, and if there is an issue, they call the vendor to resolve it. When it comes to a corporate customer and their cloud provider, though, things aren’t quite so simple. An SLA outlines expectations and reporting so that the customer is aware of what to anticipate and who is responsible for what.
- Guarantees service level objectives. The cloud provider accepts the client’s SLOs and can demonstrate that they were met. There is a clear reaction and remedy method if there is an issue. This also safeguards the service provider. When a customer saved the money by accepting to a 48-hour data recovery window for certain of their apps, the supplier is fully justified in taking 47 hours.
- Quality of service. There is no need for the consumer to estimate or make assumptions about service levels. They receive regular information on the parameters that matter to them. If the cloud provider breaks a contract, the customer can seek redress through negotiated penalties. However these penalties will not always compensate for lost income, they can be powerful motivators when a cloud provider is paying $3,000 per day for a service outage.
The SLA violation can be predicted and rectified by various algorithms one of the helpful method is using Machine Learning technique.
1.7 ML based Resource Allocation
In cloud computing, Resource Allocation (RA) is a method of distributing available resources to necessary cloud applications over the internet. It necessitates the type and quantity of resources that each application need to complete a user job. Machine learning (ML) is a form of artificial intelligence (AI) that allows software programs to improve their prediction accuracy without being expressly designed to do so. In order to anticipate new output values, machine learning algorithms use past data as input.
Enterprises may use machine learning in the cloud to test and launch smaller projects first, then scale up as demand and necessity grow. The pay-per-use concept has a number of advantages.
Cloud computing has had a significant influence on the Information Technology (IT) sector, and many businesses, like Google, Amazon, Microsoft, and Alibaba, are vying to deliver more powerful, dependable, and cost-effective cloud services. Furthermore, IT companies are attempting to restructure their business services in order to receive the full benefits of cloud computing. Service providers maintain cloud resources according to an on-demand pricing system in a cloud platform, and they must secure their own profitability while delivering high QoS and maximum customer happiness. As a result, resource allocation is essential in cloud computing and has an impact on QoS, overall system performance, and SLA, which measures customer satisfaction [14].
When the data is already in the cloud, using a cloud-based ML service makes perfect sense. Transferring big amounts of data is time-consuming and costly. Businesses may easily experiment with machine learning capabilities on the cloud and scale up when projects go live. The creation and implementation of algorithms that enable computers to generate behaviors based on empirical data, such as sensor information or databases, is referred to as machine learning. Automatically learning to detect complicated patterns and making intelligent judgments depending on data is a key focus of Machine Learning; The problem is that the set of all potential behaviors given all possible inputs is just too difficult to be described in a generic programming language, thus programs must, in effect, automatically explain programs.
1.7.1 Cloud Resource Management
For multi-objective optimization, cloud resource management necessitates complicated rules and judgments. Re-source management is one of the most essential components of cloud computing for IaaS. Workload estimate, job scheduling, VM consolidation, resource optimization, and energy optimization are just a few of the resource management activities that machine learning is being utilized for. There are five different types of rules:
- Load balancing
- Admission control
- Capacity allocation
- Energy conservation
- Assurances of service quality
Basic mechanism for resource Management
Rather than relying on ad hoc approaches, in cloud allocation strategies must be based on a systematic strategy. The four fundamental techniques for establishing resource management strategies in cloud computing are as follows:
- Control theory – Feedback is used in control theory to ensure system stability and estimate transient behavior, although it can only predict local behavior.
- Machine learning – Machine-learning approaches have the benefit of not requiring a system performance model. This approach might be used to coordinate the actions of several autonomous system administrators.
- Utility-based – A performance model and a method to connect user-level performance with cost are required for utility-based techniques.
- Market-oriented – It does not need any system model like conducting auctions for set of resources.
A sophisticated system with a high number of shared resources is referred to as a cloud computing platform. These are susceptible to unforeseen requests and can be influenced by circumstances outside of your control.
1.7.2 ML in cloud
There are 3 major ways in which machine learning in the cloud will act as a boon for businesses. These are:
- Cost Efficiency
The cloud has a model for pay-per-use. This removes the need for businesses to invest in heavy-duty and costly machine learning systems that are not always used daily. And this is true for most businesses because machine learning is used as a tool and not as a modus operandi.
Fig 1.3 Benefits of cloud with ML [113]
If AI or machine learning were to increase workloads, the pay-per-sec approach of the cloud would be convenient to assist businesses reduce expenses. GPUs can utilize their power without investing in high-cost equipment. Cloud machine learning allows inexpensive data storage and improves the cost-effectiveness of this technology.
- No special expertise required
Only 28 percent of businesses have expertise with AI or machine learning, according to Tech Pro study. The need for machine learning is growing and machine learning’s future scope is promising. Artificial intelligence features may be deployed using Google Cloud Platform, Microsoft Azure and AWS without needing a deep or specialized expertise. The SDKs and APIs are already available to natively integrate machine learning functions.
- Easy to scale up
When a business experiments with machine learning and its possibilities, it makes no sense for it to go completely, to complete it just at first. Using cloud-based machine learning, companies may initially test and deploy smaller projects on the cloud, then grow demand and requirement. The pay-per-use approach makes it easier to access more powerful features without the requirement for more advanced gear.
1.7.3 Advantages of ML in the cloud
- “Companies/enterprises may use the cloud to experiment with machine learning technology and scale up as needed as projects go live and demand grows.
- Companies who want to employ machine learning for their business but don’t want to invest a lot of money will find the pay-per-use model of cloud platforms to be an inexpensive option.
- To access and use numerous ML functions in the cloud, you don’t need sophisticated Data Science expertise”.
Workload estimate, job scheduling, VM consolidation, resource optimization, and energy optimization are only some of the resource management activities that machine learning is being utilized for.
1.8 Organization of Thesis
Chapter 2 devises the review of existing literature and their comparative analysis. Chapter 3 discusses a load balancing-based hyper heuristic method for work scheduling in a cloud setting. In Chapter 4, we looked at how to use a risk management framework in the cloud to implement a SLA-aware load balancing approach. In chapter 5, an inside view is made on how Honey bee optimized hyper heuristic algorithm and SLA-Aware Risk Management Framework are efficient than other techniques followed by chapter 6 summed up the research with its concluding points and future scope of the work.
CHAPTER-2
LITERATURE SURVEY
This chapter is discussed the survey about the cloud computing environment and virtual machine process. It is also studied about the load balancing process and scheduling approaches for improve the system performance and to protect the system against failure. A risk management topic also discussed here which is used to predict the risk and rectified while achieving the better task scheduling process and good load balancing technique. One of the major risks is SLA violation handling also discussed here and resource allocation to the virtual machine with the help of the machine learning concept also presented here.
2.1 Cloud Computing
The authors [15] proposed a unified Cloud service measuring index in order to give a single, complete methodology for multi-level Cloud service assessment. They defined 8 top-level Cloud service qualities and 65 specific key performance metrics for evaluating these qualities for a comprehensive and effective performance review. They used ‘‘Multi-Attribute Global Inference of Quality for a good analytical rating of the targeted Cloud services, which took into account the hierarchical connection of performance factors. This approach takes into account user’s needs for Cloud service attributes in terms of attribute weights and allows you to pick all or just the ones you want.
Authors in [16] developed a reliable service composition discovery technique for meeting user needs in a cloud context, including behavioral restrictions. They proposed a service composition discovery technique after designing a global service composition discovery framework depending on semantic connections between characteristics. Then they came up with a mechanism for identifying behavioral consistency. This technique significantly enhances user anticipated behavior and service composition consistency, making the service composition identified by this technique in cloud computing more reliable.
The study [17] used S-AlexNet Convolutional Neural Networks and Dynamic Game Theory to develop a security reputation model (SCNN-DGT). It’s also utilized in the Internet of Things (IoT) to secure the confidentiality of health data. With the help of the S-AlexNet convolutional neural network, the text data about user health data is first pre-classified. Then, depending on dynamic game theory, a suggestion incentive approach is proposed. The suggested work improves the dependability of mobile terminals while also strengthening the data security and privacy safety of mobile cloud services.
The study [18] proposed a Reliable Trust Computing Mechanism (RTCM) focused on multisource feedback and fog computing fusion. To improve the identification of malicious feedback nodes, a new measure for social sensor node trust is created, and multisource feedback trust values are collected at the sensing layer. Furthermore, the fog computing devices gather the sensing layer’s trust feedback information and conduct the recommendation trust calculation, that reducing communication time and computation overhead. Finally, a fusion algorithm is used to combine multiple forms of feedback trust values, overcoming the artificial weighting and subjective weighting limitations of previous trust methods.
For the screening of upstream Advanced Metering Infrastructure (AMI) traffic, the authors of [19] suggested a cloud-centric collaborative security service model. It also provides a service placement strategy for the proposed framework that is collaboration-aware. A quadratic assignment issue was devised as part of the placement strategy to reduce delay.
The author [20] conducted a quantitative assessment of security investments’ effects on security protocols and service availability. This analysis yields the best security expenditure for service availability and the smallest full service availability investment criterion. Finally, the relationship between them is investigated in order to help cloud computing providers choose the optimal strategy for integrating service and security efforts.
“Priority-aware resource allocation algorithms that account both host and network resources were proposed by the study’s authors [21].To decrease the possibility of network congestion caused by other tenants, the Priority-Aware VM Allocation (PAVA) algorithm allocates VMs of the high-priority application on closely linked hosts. Bandwidth allocation with a setup of priority queues for each networking device in a data center network handled by a Software-Defined Networking (SDN) controller also ensures the needed bandwidth for a vital application. In a multi-tenant cloud data center, the suggested techniques can distribute adequate resources for high-priority applications to fulfill the application’s QoS demand”.
The study [22] proposed a new trust evaluation paradigm for cloud service security and reputation. This model combines security- and reputation-based trust analysis methodologies to support the evaluation of cloud services in order to assure the security of cloud-based IoT contexts. To analyze the security of a cloud service, the security-based trust evaluation approach uses cloud-specific security measures. In addition, the reputation-based trust evaluation technique uses feedback rankings on cloud service quality to estimate a cloud service’s reputation.
The author [23] presented an ad-hoc mobile edge cloud that leverages Wi-Fi Direct to link neighboring mobile devices, exchange resources, and integrate security services. The proposed technique combines a multi-objective resource-aware optimization method with a genetic-based methodology to allow intelligent offloading decisions using adaptive profiling of contextual and statistical data from ad-hoc mobile edge cloud devices. To minimize energy consumption and processing time, the proposed solution employs a combination of components that rely on profiling, multi-objective optimization techniques, and heuristics.
Authors in [24] designed a novel multi-layered cloud-based approach. This approach is intended to simplify the administration of underlying resources and to create fast flexibility, allowing end users to access limitless computing capacity; it takes into account energy usage, security, and multi-user availability, scalability, and deployment concerns. To decrease the use of computer resources, an energy-saving technique is employed. To secure sensitive data and prevent hostile assaults in the cloud, security components have been incorporated.
The authors of the study [25] recommended using descriptive values to forecast multi-step ahead wind speed using an S along with Seasonal Autoregressive Integrated Moving Average (SARIMA) based hybrid method. The explanatory factors are calculated first, and a wind speed forecast is made. Recursively, they were able to get this multi-step forward forecasting.
Authors in [26] proposed a neural network approach called Neural Decomposition (ND) for analyzing and extrapolating output timings. By executing a trial for Fourier-like decomposition into sequences of sinusoids, joined by blocks with non-periodic functions that are active, blocks having a sinusoidal activation system were used to discover linear patterns as well as other non-periodic components.
The study [98] introduced a hybrid cryptography method that uses encryption to efficiently transfer data over the cloud. To create the hybrid encryption algorithm, more than one algorithm was combined. The user can select the plain text data that needs to be encrypted using the hybrid cryptographic method.To protect data saved in the cloud, the suggested hybrid cryptography algorithms include RSA (Rivest Shamir Adleman) and AES (Advance Encryption Standard).
Authors in [102] proposed a unique paradigm for Network Traffic assessment in Cloud platform. The network traffic data is gathered in the cloud and stored in a cloud database, where a machine learning system is created. In a cloud computing environment, network traffic data is sent to a classification or clustering machine based on whether it is labelled or unlabelled. The system may be controlled remotely and has a scalable architecture.
2.2 Virtual Machine
The study [27] presented a method to enhance the energy efficiency of cloud data centers namely, a Virtual Machine Consolidation method with Multiple Usage Prediction (VMCUP-M).Multiple usages in this sense refer to both resource kinds and the time range used to forecast future usage. According to the local history of the evaluated servers, this method is run during the virtual machine consolidation stage to predict the long-term usage of different resource categories. The combination of present and anticipated resource usage enables accurate classification of overloaded and under-loaded servers, resulting in lower load and power usage following consolidation.
The study [28] created a load detection method for hosts in order to prevent rapid VM migration by determining the future condition of over-utilized/under-utilized hosts. They also proposed a virtual machine placement approach for establishing a group of host candidates obtaining migrated VMs in order to reduce VM transformations in the future.
The author [29] proposed a lower complexity Multi-Population Ant Colony System method with the Extreme Learning Machine (ELM) prediction (ELM_MPACS). The method used ELM to forecast the host state, and then transferred the virtual machine on the overloaded host to the normal host, while consolidating the virtual machine on the under-loaded host to another under-loaded host with greater utilization. Multiple populations create migration plans at the same time, and local search improves each population’s findings to decrease SLA violations.
The authors of [30] proposed altering a nova scheduler to enhance application performance in terms of execution time and processor usage by using a multi-resource VM placement technique.
To address the security risks to VMs during their whole lifespan, the study [31] presented a unique VM lifecycle security protection paradigm based on trusted computing. A notion of the VM lifespan is provided, which is split into the various active states of the VM. Then, a proper security framework based on trusted computing is created, which may expand the trusted relationship from the trusted platform module to the VM and safeguard the VM’s security and dependability throughout its lifespan.
The study [32] proposed a virtual machine placement technique and also a host overload / under-load recognition method for energy savings and SLA-aware virtual machine consolidation in cloud data centers, based on their recommended reliable, simple linear regression model of regression. Unlike traditional linear regression, the proposed methods alter an estimate and squint at over-prediction simultaneously adding the error to the forecast.
The authors of [33] suggested an approach based on the Energy-Aware concept for VM migration in automotive clouds. They also suggested a new VM migration strategy depend on the energy costs of migration, taking into account the energy costs of VMs in the cloud and cloudlets, including the energy costs of communication among cloudlets, clouds, and vehicles. It also resulted in a 5% decrease in VM drop migrations.
A virtual machine deployment selection method is proposed focused on a double-cursor control mechanism for the resource consumption status of Processor and memory was given in the study [34], which achieved a binocular optimization balance to some extent. The suggested method is utilized to increase cloud data center resource utilization, lower virtual machine migration rates, and minimize physical resource energy usage.
The study [35] proposed a technique for multi-objective resource allocation for those VMs based on Euclidean distance, as well as a data center migration strategy for VMs. HGAPSO, a hybrid technique that combines Genetic Algorithm (GA) and Particle Swarm Optimization (PSO), which allocates VMs to Physical Machines (PMs).Not only does the recommended resource management based on HGAPSO and virtual machine transfer minimize power and resource waste. As a result, there are no SLA violations in the cloud data center [36].
The author [37] suggested a Global Virtual-Time Fair Scheduler (GVTS), which ensures global virtual time fairness for threads and thread groups, even when they operate across multiple physical cores. The hierarchical enforcement of destination virtual time is used by this novel scheduler to improve the scalability of schedulers that are knowledgeable of the topology of CPU organizations.
The study [38] suggested virtual machine (VM) trading techniques in which idle Reserved Instance (RI) of Service Providers (SPs) with VM requirement less than the number of contractual RI are moved to SPs with VM requirement more than the number of contractual RI. They looked into two techniques as VM trading frameworks: RI with Self-help Effort (RISE) and RI with Mutual Aid (RIMA). The suggested virtual machine trading strategies reduced the number of virtual machines needed for On-Demand Instances (ODI).
The authors of [39] developed a dynamic reconfiguration system named Inter-Cloud Load Balancer (ICLB) that permits scaling up and down of virtual resources while avoiding service outages and communication problems. It comprises an inter-cloud load balancer that distributes incoming user HTTP (Hypertext Transfer Protocol) traffic over various instances of inter-cloud applications and services, as well as dynamic resource reconfiguration to meet real-time needs.
The authors of [99] presented methods for power-aware virtual machine scheduling and migration. The power savings are obtained by consolidating virtual machines onto a smaller number of servers and placing idle nodes into sleep mode. The distribution and consolidation of virtual machines on a server is dependent on server efficiency, i.e. minimizing energy usage while maximizing utilization.
The research [122] researched a virtual slice environment-aware paradigm that improves energy efficiency and addresses intermittent renewable energy sources. The virtual slice is an optimum flux allocated to virtual machines in a virtual data center taking into consideration traffic, VM locations, network physical capacity and the availability of renewable energy. They developed and then suggested an optimum solution for the issue of virtual slice assignment using different cloud consolidation methods.
The study [123] presented CloudNet’s cloud computing architecture connected with a virtual private network (VPN) infrastructure to offer smooth and safe connection between company and cloud data center locations. CloudNet offers improved support for the live WAN transfer of virtual machines in order to fulfill its goal of effectively combining geographically dispersed data center resources. In particular, they introduced a number of optimisms that reduce the costs of transferring storage and virtual machine memory over low bandwidth and high-latency internet connections during migration.
The author of [124] proposed a new method to best address the issue of host overload detection for any known fixed workloads and a given state configuration by maximizing the average time intermigration under the defined QoS model based on the Markov chain model. They heuristically adjust the method for uncertain, non-static workloads using a technique used to estimate multisize sliding windows.
The research [125] a framework suggested, called CoTuner, for coordinated VM and resident apps setting. The core of the framework is a model-free hybrid strengthening learning technique that combines the benefits of the Simplex method and the RL method and is further improved by the use of system-wide exploration policy. Experimental findings using TPC-W and TPC-C benchmarks in Xen-based, virtualized settings show that CoTuner can conduct a virtual server cluster in an optimum or nearly optimal flight configuration status in response to changing workloads.
2.3 Load Balancing
A Dynamic Load-Balanced Scheduling (DLBS) technique was proposed in the study [40] to utilize network efficiency when dynamically controlling the workload. They presented the DLBS task and created a series of successful heuristic scheduling algorithms for both traditional Open Flow network approaches that preserve data flow by each time slot.
The author [41] presented a Resource Aware Load Balancing Algorithm (RALBA) to ensure task distribution while maintaining balance based on VM capabilities estimation. The RABLA technique has two actions: (i) VMs are scheduled depending on their computational capability, and (ii) task mapping is done by picking the VM with the earliest completion time. RALBA, on the other hand, does not help Cloud tasks with SLA-aware scheduling. As a result, resource-based SLAs and time-limited cloudlets may not be well-prepared.
Authors in [42] conducted a study of the difficulties and drawbacks associated with present load balancing approaches in order to build a high-efficiency technique. They gave a thorough examination of the many types of load balancing, scheduling, and task-based load balancing methods used in the cloud.
The authors of [43] conducted a meta-analysis of published load balancing methods that were achieved through server consolidation. Server consolidation-based load balancing improves resource efficiency and can help data centers enhance their QoS metrics while also expanding their applications. The study [44] provided a load-balancing approach based on the ACO algorithm. The parameters of ant colony function are improved using this method.
The study [45] provided a comprehensive overview of current VM transformations, as well as techniques for determining which policies to use based on the advantages and drawbacks. They offered computational methods and their scopes with many elements such as SLA results degradation, VM migrations, and so on.
The study’s authors [100] presented a method for balancing the demand on storage servers while maximizing server capabilities and resources. It decreases the number of requests that are delayed, as well as the total response time of the system. It also takes into account the physical characteristics of a server, such as the number of Processor cores available, the size of the request queue, and the buffer used to hold incoming customer requests.
A novel Trust and Packet load Balancing based Opportunistic outing (TPBOR) protocol was described in the study [101].By using trustworthy nodes in the routing operation, the proposed approach is energy efficient as well as safe. In addition, the suggested protocol balances network traffic and evenly distributes traffic load across the network.
The study [114] introducing a load balancing and cloud application scaling energy-aware operating paradigm. The fundamental idea of their approach is to define an energy-friendly operating regime and to increase the number of servers in this system. Idle and lightly loaded servers are moved to one of the sleeping modes for energy conservation.
The research [115] offered a time and space efficiency adaptive method in a heterogeneous cloud. In order to improve the execution time of the map phase, a dynamic speculative execution approach is described and a prediction template is utilized for quickly predicting task performance times. A multi-objective optimization method combines the prediction model with the adaptive solution to improve space-time performance.
The study [116] the compromise between electricity usage and latency in transmission in the fog cloud computing system was studied. They developed a workload allocation problem which indicates the optimum distribution of the task between fog and the cloud towards minimum energy consumption with a restricted service time. The issue is addressed using an approximation method by dividing the primary problem into three subsystem subproblems that may be handled accordingly.
The authors in [117] Proposed a new architecture and two unified load balance algorithms. Current research demonstrates that their methods have a low computing cost, need relaxed precision in the estimate of the power price, and ensure user demands a service completion times. Compared to plans which use either geographical load balancing or temporal load balancing alone, thorough assessments show that the proposed spatial-temporal load balance approach substantially lowers distributed IDC energy costs (Internet Data Centers).
The authors of [118] Suggest a Cloud-hosted SIP (Session Initiation Protocol) Virtual Load Balanced Call Admission Controller (VLB-CAC). VLB-CAC calculates the optimum call admission rates and signal routes for admitted calls and also optimizes the assignment of SIP server CPU and memory resources. A novel linear programming model derives this optimum solution. This model needs some essential SIP server information as an input. VLB-CAC also has an autoscaler to address resource constraints. The suggested system is implemented as a virtual test bed in Smart Applications on Virtual Infrastructure (SAVI).
The research [119] Proposed inter-domain service transfer decision system to balance computational demands across different cloud domains. The system’s objective is to maximize the benefits for both the cloud system and users by reducing the number of service refusals, which substantially decrease the level of user happiness. To this purpose, they construct the decision-making process for service requests as a semi-Markov decision process. Optimal choices on service transfer are achieved by taking system revenues and expenditures together.
The authors of the study [120] Proposes iAware, a lightweight VM live migration method that is aware of interference. It experimentally captures the fundamental connections between VM performance interference and key variables which are accessible in practical terms via actual benchmarking tests on Xen virtualized cluster architecture. iAware jointly estimates and reduces migration and interference with co-location across VMs by developing a simple demand-supply multi-resource model.
The research [121] proposed a virtualization architecture considering the issue of load balancing. The suggested framework benefits from the flourishing use of the DVS and the flourishing usage of OpenFlow protocols. First, the system adapts diverse patterns of network communication by allowing arbitrary traffic matrices between VMs in virtually private clouds (VPCs). The sole limitation of network flows is that the network interface of a server is bandwidth. Second, the framework provides load balancing using a sophisticated connection creation mechanism. The program takes the bare metal data center designs and the changing network environment as input and adapts an international overlap on each connection. Finally, the suggested framework focuses on the design of the fat tree, which is extensively utilized in today’s data centres.
2.4 Scheduling Approaches
A Hyper-Heuristic Scheduling Algorithm (HHSA) was given in the research [46]. This method reduces the time it takes to schedule jobs. The ACO computation was given by the study’s authors [47] for completing distributed computing undertaking booking. The study [48] described a cloud-based remedy to the issue of job scheduling. A LAGA (Load Balance Aware Genetic Algorithm) is used in combination with min-min and max-min methods in this method [49].
The authors of [50] devised a dynamic task scheduling strategy based on three swarm intelligence approaches: ACO, ABC, and PSO, in order to reduce the time it takes to complete a given set of jobs. Authors in [51] designed a system centered on a Genetic algorithm for job scheduling with the goal of lowering total schedule makespan time and increasing resource utilization. The research [97] suggested a novel round robin scheduling technique that helps to increase CPU efficiency.
Work planning for cloud registration is investigated in the research [52].After conducting study and analysis on the subject, the team decides on a project that will take the shortest amount of time to complete and will cost the least amount of money. The research [53] focused on a few of the most important work process planning approaches. It provides a complete review of such distributed computing approaches, as well as a point-by-point grouping of them.
The research [54] presented the Ant Colony Optimization (ACO) based Load Balancing (LBACO) method was used to develop a job scheduling solution for cloud computing environments. This approach shortens the time it takes for tasks to complete by balancing the system’s load.
To overcome the scheduling problem, the authors of [55] devised an improved ant colony approach. Constraint functions are used to modify the nature of the scheduling arrangements in a practical way with a specific end goal in mind: to get the best possible results.
The author [56] addressed a scheduling method that incorporates a genetic algorithm, as well as min-min and max-min, and demonstrates how min-min and max-min are presented. The authors of the study [48] proposed a unique scheduling technique that enhances the fundamental particle swarm optimization (PSO) algorithm and categorizes fitness values using a self-adapting inertia weight and mutation process.
The study [57] concentrated on the problem of job security planning in a distributed computing environment. The authors of [58] presented an algorithm that successfully schedules jobs to the right servers while lowering makespan time and achieving improved load balancing outcomes.
The author [59] presented an efficient task scheduling method based on Particle Swarm Optimization and a chaotic perturbation technique, which results in a quicker convergence time and a shorter makespan time.
The study [60] focused on a scheduling method based on particle swarm optimization (PSO) that takes into account both current load and transmission cost and uses an inertia weight to effectively execute local and global searches while avoiding local search sinking. To minimize makespan and improve resource usage, the study [61] used a hybrid approach based on particle swarm optimization (PSO).
Authors in [62] the HABC method, which is a Heuristic Task Scheduling with Artificial Bee Colony algorithm for virtual machines in heterogeneous Cloud environment. It’s a new job scheduling and load balancing method for virtual machines in diverse settings, with the goal of reducing the system’s makespan time. Even when the number of jobs is increased and various types of information are dispersed, the suggested technique reduces the makespan.
The authors of [103] conducted a comparative analysis of several methods for their rationality, feasibility, and adaptability in a cloud scenario, after which they attempted to suggest a crossover method that might be used to enhance the present stage. With the objective of encouraging the cloud providers to improves their service quality.
The study [126] proposed a resource provisioning and scheduling strategy for scientific workflows on Infrastructure as a Service clouds. They presented an algorithm based on the meta-heuristic optimization technique, particle swarm optimization, which aims to minimize the overall workflow execution cost while meeting deadline constraints.
Authors in [127] proposed a novel rolling-horizon scheduling architecture for real-time task scheduling in virtualized clouds. Then a task-oriented energy consumption model is given and analyzed. Based on their scheduling architecture, they develop a novel energy-aware scheduling algorithm named EARH for real-time, aperiodic, independent tasks. The EARH employs a rolling-horizon optimization policy and can also be extended to integrate other energy-aware scheduling algorithms. Furthermore, they proposed two strategies in terms of resource scaling up and scaling down to make a good trade-off between task’s schedulability and energy conservation.
The authors of the study [128] presented two key contributions. (1) They proposed an autonomous synchronization-aware VM scheduling (SVS) algorithm, which can effectively mitigate the performance degradation of tightly-coupled parallel applications running atop them in over-committed situation. (2) They integrate the SVS algorithm into Xen VMM scheduler, and rigorously implement a prototype.
The research [129] introduced PRISM, a fine-grained resource-aware Map-Reduce scheduler that divides tasks into phases, where each phase has a constant resource usage profile, and performs scheduling at the phase level. They first demonstrated the importance of phase-level scheduling by showing the resource usage variability within the lifetime of a task using a wide-range of Map–Reduce jobs. They then presented a phase-level scheduling algorithm that improves execution parallelism and resource utilization without introducing stragglers.
The authors in [133] proposed an elastic resource provisioning mechanism in the fault-tolerant context to improve the resource utilization. On the basis of the fault-tolerant mechanism and the elastic resource provisioning mechanism, they designed a novel fault-tolerant elastic scheduling algorithms for real-time tasks in clouds named FESTAL, aiming at achieving both fault tolerance and high resource utilization in clouds.
The study [134] proposed avGASA, a virtualized GPU resource adaptive scheduling algorithm in cloud gaming. vGASA interposes scheduling algorithms in the graphics API of the operating system, and hence the host graphic driver or the guest operating system remains unmodified. To fulfill the service level agreement as well as maximize GPU usage, they proposed three adaptive scheduling algorithms featuring feedback control that mitigates the impact of the runtime uncertainties on the system performance.
2.5 Risk Management
The study [63] proposed a threat-specific risk assessment process that takes into account multiple cloud security attributes (e.g., vulnerability data, attack possibility, and effect of every attack related with the recognized threat(s)) but also client-specific cloud security demands. It enables a cloud provider’s security controller to make good judgments about mitigation techniques to safeguard particular customers’ outsourced computing assets from specific threats depending on their specific security demands. The suggested technique is not restricted to cloud-based systems; it may be readily applied to other networked systems as well.
The authors of [64] suggested an optimum security risk management approach to comprehensively limit the risks of a DoS (Denial of Service) attack and SLA breaches that might occur in the 5G edge-cloud ecosystem. A cyber risk-aware controller is developed through using Semi-Markov Decision Process architecture to determine the best admission, placement, and migration of a service while taking user taxonomy and service needs into account. To prepare the way for a secure edge-cloud process, a novel cost model is presented that balances the intended security risks, but also the cost and benefit of a secure service delivery.
The study [65] concentrated on a specific element of risk assessment in cloud computing: techniques within an approach that cloud service providers and consumers may use to assess risk throughout service development and operation. They highlighted the different stages of the service lifecycle during which risk assessment occurs, as well as the risk models that have been created and applied.
A Secret Sharing Group Key management protocol (SSGK) was suggested in the study [66] to safeguard the process of communication and exchanged data from unwanted access. The shared data is encrypted using a group key, and the group key is distributed using a secret sharing method in SSGK. The suggested approach significantly reduces the security and privacy concerns associated with data sharing in cloud storage while also saving storage space.
The study’s authors [67] proposed a decentralized and trustworthy Mobile Device Cloud infrastructure based on BlockChain (BC-MDC).By integrating a plasma-based blockchain into the MDC, BC-MDC facilitates decentralization and avoids dishonesty. They created four clever contracts to manage worker registration, task posting/allocation, rewarding, and punishing in a distributed manner.MDC job allocation is sometimes described as a stochastic optimization issue that minimizes both the long-term processing cost and the probability of task failure. The suggested method has a cheap cost of use and a high degree of accuracy.
Under server-side assaults, the study [68] proposed a Risk-aware Computation Offloading (RCO) mechanism to spread computation workloads safely across geographically scattered edge sites.RCO considers prospective attackers’ strategic actions in the edge system and strikes the right balance among risk management and service latency reduction. The RCO problem is formulated using the Bayesian Stackelberg game, which specifies an acceptable relationship among the edge system and the attacker. The Bayesian Stackelberg game, in especially, reflects the unpredictability of attacker behavior and allows RCO to operate even if the edge system does not know who it is up against.
Authors in [69] suggested a new Cloud Security Risk Management Framework (CSRMF) to aid businesses embracing Cloud Computing (CC) in identifying, analyzing, evaluating, and mitigating security threats in their Cloud infrastructures. The CSRMF, unlike standard risk management frameworks, is inspired by the companies’ business objectives. It enables any company using CC to be knowledgeable of cloud security threats and match low-level management actions with high-level business goals. It is intended to address the effects of cloud-specific security threats on a company’s business objectives. As a result, companies may undertake a cost-benefit analysis of CC technology adoption and obtain a sufficient degree of trust in Cloud technology. Cloud Service Providers (CSPs), on the other hand, may enhance productivity and profitability by controlling cloud-related threats.
The study [130] Presented new disaster-aware data center placement and Content Management methods in cloud networks which may minimize such loss by avoiding installation in disaster-induced places. You initially address a static disaster-conscious data center and content placing issue by adopting a linear integer program with the aim of minimizing the risk of content loss. They then developed an algorithm for catastrophe conscious dynamic content management that could adapt the current placement to dynamic circumstances. In this method, while lowering the total risk and making the network aware of disasters, reducing the use of network resources and meeting quality of service standards may also be accomplished.
The study [131] proposed the Cloud Compute Commodity (C3) Cloud Abacus pricing framework to suit both parties. They utilize financial option theory ideas and algorithms to create Clabacus. They developed a generic formula known as the Compound-Moores law that identifies technical advancements in resources, inflation and depreciation rates and so on. They link these Cloud parameters to price parameters, so that the Pricing Algorithm option may be effectively modified to calculate the Cloud resource price. Using financial-at-risk (VaR) analysis, the calculated resource pricing is adjusted to reflect the cloud provider’s inherent hazards. They presented fluctuating logic and evolutionary algorithm methods to calculate the supplier’s VaR resources.
The research [132] proposed a new data hosting system (CHARM name) integrating two major required functionalities. The first is to choose many acceptable clouds and a suitable redundancy method to store data with minimized money costs and assured available availability. Second, a transition process is initiated to distribute data in accordance with changes in data access patterns and cloud prices.
2.6 SLA violation Handling
The author [70] introduced SLA-aware autonomic Technique for Allocation of Resources (STAR), a SLA-aware autonomic resource management technique aimed at lowering SLA violation rates for effective cloud service delivery. STAR’s major goal is to lower the number of SLA violations and increase customer happiness by meeting their QoS standards. STAR also looked at other QoS factors including completion time, cost, delay, dependability, and availability to see how these affected SLA violation rates. However, energy efficiency, attack detection rate, resource usage and resource contention, scalability, and other factors were not taken into account.
The study [71 & 72] created a successful overbooking model while also acknowledging the necessity for best solution. They discovered that using the optimal strategy, the recommended overbooking technique will increase a federated company’s profits while lowering the chance of SLA violation. If a provider’s ability is reasonably high, and the provider uses the proposed overbooking technique frequently, the provider’s SLA breach may be denied and the provider’s profit maximized.
The authors of [73] introduced ATEA (Adaptive Three-threshold Energy-Aware algorithm), a novel virtual machine (VM) allocation method that makes effective use of previous data from VM resource use. It’s a new virtual machine deployment technique that combines an adaptive three-threshold approach with VM selection rules. Dynamic thresholds consume less energy than fixed thresholds. It effectively cuts down on energy usage and SLA violations.
The authors of the study [74] proposed the Balanced Resource Consumption (BRC) and Imbalance VM with Minimum Migration Time (IBMMT). The BRC-IBMMT approach is a balanced resource consumption approach that aims to optimize resource consumption efficiency while keeping a fair balance among conflicting energy consumption correlation goals and SLA breaches.
From a risk management standpoint, the research [75] created the SLA violation discovery and minimization process. To regulate SLA breaches, they suggested RMF-SLA, a Risk Management-based abatement method. SLA monitoring, violation prediction, and decision reference are all part of the SLA development process.
The study [76] proposed using a quality management criterion to improve cloud storage SLAs and meet industry QoS standards on both levels. The platform employs Reinforcement Learning (RL) to provide a technique for employing VM that can respond to program changes in order to ensure QoS for all client groups. Infrastructure costs, network capacity, and service demands are all factors in these improvements.
The study [77] offered two energy-efficient approaches based on consolidation that decreases energy usage and SLA breaches. They also improved the current Enhanced-Conscious Task Consolidation (ECTC) and Maximum Utilization (MaxUtil) methods, which aim to cut down on energy usage and SLA breaches. In basis of energy, SLA, and migrations, the suggested approach performs well. The suggested approaches achieve the aforementioned objectives by picking the most energy-efficient and CPU-capable servers.
Authors in [78] proposed a Risk Supervision technique for preventing SLA breaches (RMF-SLA), which assists cloud facility operators in reducing the risk of facility violations. This technique employs the Fuzzy Inference System (FIS), which investigates inputs such as the predicted trajectory of customer behavior, the supplier’s danger mindset, and the service’s dependability.
The authors of the study [79] proposed an Adaptive and Fuzzy Resource Management approach (AFRM), where the most recent resource values of every virtual machine are acquired via environment sensors and transmitted to a fuzzy controller. Then, in each iteration of a self-adaptive control cycle, AFRM evaluates the incoming data to make a choice on how to reassign resources. To meet QoS demands, all membership functions and rules are constantly updated depending on workload modifications. AFRM drastically decreases SLA breaches and costs while substantially increasing Resource Allocation Efficiency (RAE).
To accommodate the dynamic behavior of cloud-based platforms, the study [80] developed a real-time and proactive SLA renegotiation approach. Depending on parameter weight-age, renegotiation is demonstrated for four different circumstances. A multi-offer generating technique is utilized to accomplish real-time decision. To enable proactive renegotiation, a unique approach to identify and forecast service breach is suggested. It allows the customer’s faith in the cloud service provider to be preserved by continuing to offer the service without interruption.
Authors in [81] proposed a novel multi-objective VM consolidation strategy centered on double thresholds and the Ant Colony System (ACS).The suggested method uses two CPU usage thresholds to determine the host load situation; VM consolidation is invoked once the host is overburdened or under-loaded. Throughout consolidation, the method uses ACS to pick migrating VMs and target hosts at the same time, with different selection rules depending on the host load state.
2.7 ML based Resource Allocation
Power Migration Expand (PowMigExpand) is a unique resource assignment technique, was introduced in the study [82]. Depending on a complete utility function, it sends user requests to the best server and assigns the best resources to User Equipment (UE).Depending on user mobility; PowMigExpand additionally moves UE requests to new servers as necessary. They also demonstrated a low-cost Energy Efficient Smart Allocator (EESA) method which uses deep learning to allocate requests to the best servers in terms of energy efficiency. The proposed methods took into account the differing load of incoming requests and their diverse nature, energy efficient server activation, and VM migration for smart resource allotment, making them the first thorough deep learning design to resolve the complex and multidimensional resource allotment problem.
The study [83] presented a DeepRM_Plus, a deep Reinforcement Learning (RL)-focused approach for solving various cloud resource management challenges efficiently. They represent the resource management approach with a convolutional neural network and apply imitation learning in the reinforcement process to decrease the best policy’s training time. The average weighted turnaround time and the average cycle time are both reduced by DeepRM_Plus.
To tackle the coordinated scheduling problem among task scheduling and resource allotment, the authors of [84] developed a two-stage task scheduling and resource allotment system that uses several intelligent schedulers. In the task scheduling step, a Heterogeneous Distributed Deep Learning (HDDL) algorithm is applied to schedule numerous jobs across various cloud data centers. The Deep Q-Network (DQN) architecture is a resource scheduler that allows virtual machines to be deployed to real servers and run. The suggested framework offers high scalability and minimal computation latency, as well as the potential to create a global near-optimum by accomplishing local optimization at each level.
The study’s authors [85] presented a Reinforcement-Learning-based State-Action-Reward-State-Action (RL-SARSA) method to address the resource management issue in the edge server and make the best offloading option for lowering system costs, such as power consumption and computation time delay. This technique is known as Offloading Decision-based SARSA (OD-SARSA). The suggested technique overcomes the majority of the problems that CPSSs (Cyber-Physical-Social Systems) experience and provides the best results in regard of volume, diversity, velocity, and truthfulness.
Two distinct dynamic methods were given in the study [86]: (i) The first technique seeks to reduce system energy usage while maintaining E2E (End-to End) service latency and accuracy; (ii) the second way focuses on improving learning accuracy while maintaining E2E service latency and a finite average energy usage. They next proposed a stochastic Lyapunov optimization-based dynamic resource allotment paradigm for Edge Machine Learning (EML).It is not necessary to have any prior understanding of wireless channel statistics, data arrivals, or data probability distributions.
Authors in [87] proposed a double offloading system to mimic the offloading operation in a real-world edge situation with multiple edge servers and gadgets. The offloading was then modeled as a Markov Decision Process (MDP) and used a Deep Reinforcement Learning (DRL) method called Asynchronous Advantage Actor-Critic (A3C) as the offloading decision making approach to manage the workload of edge servers and minimize the overhead in considerations of energy and time. Self-adjustment and overhead reduction are significantly improved.
To minimize total system latency, the study [88] presented an LSTM-based resource placement. To reduce system latency, they initially defined the radio resource placement issue as a convex optimization issue. Second, they devised a Convolutional LSTM- (ConvLSTM-) centered traffic prediction to estimate traffic of complicated slice services in automotive networks, which is employed in resource allocations processing, to further reduce latency. In addition, three types of traffic are taken into account: SMS, phone, and web traffic. Finally, they apply the primal-dual interior-point approach to investigate the ideal slice weight of resources for reducing the system total latency based on the projected outcomes, namely the traffic of each slice and user load distribution.
The major goal of the study [104] was to minimize transmission time in a probabilistic flow network without sacrificing Quality of Service. Fixing a likelihood of successful transmission threshold, data exchange begins as soon as a trustworthy shortest path among the supplied source and the destination is found, i.e., a path with a higher likelihood of successful delivery than expected (threshold).If a path meets the time threshold but not the maintenance budget restriction, an adjustment mechanism is used to keep the service level at a minimum. The study [105] compared the methods utilized by different authors in constructing algorithms and looked at strategies to enhance their performance.
The authors of [106] proposed a new macroeconomic prediction system based on the ant colony algorithm and the improved multimedia assisted BP neural network architecture. As a result, whenever the operational predict that must define the analysis and this rule, macroeconomic prediction foundation predicts the object history and current operating legislation. Because of the selected fault prediction technology’s limitations and forecasting approach, the forecasting outcome can be imprecise.
The research [107] applied neural networks to the finance field. In this study, the utility of an artificial neural network for estimating an individual’s FL (Financial Literacy) level was investigated.
2.8 Research Gap
Load Balancing still remains a critical issue in designing scheduling algorithms. Several researchers present their work in this regard and subsequently proposed combination of different heuristics, but did not effectively applied the load balancing concept using another heuristic approach. Accuracy of prediction and fine-tuning of threshold value is the major objective of the proposed work and existing works lags in this context only.
The threshold value is the significant part of handling the SLA violation. Still many papers are choosing this value randomly without any mathematical analysis. In our work, we are trying to handle this issue by utilizing two thresholds value.
2.9 Research Objective
The purpose of this research work is to produce an effective load balancing with good service level agreement in cloud computing environment. The major goal of the proposed work includes the following:
- To provide an effective load balanced scheduling solutions to minimize the makespan time.
- To avoid virtual machine overloaded stage by assign jobs from overloaded machine to under-loaded machine.
- To provide better quality of service with SLA violation abatement with the help of SLA-Aware Risk Management Framework (SA-RMF).
CHAPTER-3
HYPER HEURISTIC ALGORITHM FOR CLOUD TASK SCHEDULING BASED ON LOAD BALANCING
3.1 Introduction to Load Balancing
Load balancing is the rational and effective distribution of network or application traffic among several servers in a server farm. Every load balancer sits between client computers and backend servers, receiving and then distributing incoming requests to the most appropriate server.
3.1.1 Purpose of Load Balancing
Load balancers are utilized to boost application capacity (the number of concurrent users) and dependability. They boost application responsiveness by reducing the load on servers from managing and keeping application and network connections, as well as executing application-specific activities.
The primary goal of load balancing is to keep every single server from becoming overburdened and perhaps failing. To put it another way, load balancing increases service availability and reduces downtime. Abnormal traffic peaks can have an impact on server performance, but load-balancing allows you to add additional servers to the group to handle the increasing number of requests.
Load balancing is possible for the following network resources:
- “Network interfaces & services such as DNS, FTP & HTTP.
- Processing through computer system assignment.
- Access to application instances.
- Connection through intelligent switches”.
3.1.2 Load Balancing Metrics
The metrics of load balancing algorithms are discussed below:
- “Throughput: This metric is used to calculate the number of processes completed per unit time.
- Response time: It measures the total time that the system takes to serve a submitted task”.
- “Makespan: This metric is used to calculate the maximum completion time or the time when the resources are allocated to a user.
- Scalability: It is the ability of an algorithm to perform uniform load balancing in the system according to the requirements upon increasing the number of nodes. The preferred algorithm is highly scalable.
- Fault tolerance: It determines the capability of the algorithm to perform load balancing in the event of some failures in some nodes or links.
- Migration time: The amount of time required to transfer a task from an overloaded node to an under-loaded one.
- Degree of imbalance: This metric measures the imbalance among VMs.
- Performance: It measures the system efficiency after performing a load-balancing algorithm.
- Energy consumption: It calculates the amount of energy consumed by all nodes. Load balancing helps to avoid overheating and therefore reducing energy usage by balancing the load across all the nodes.
- Carbon emission: It calculates the amount of carbon produced by all resources. Load balancing has a key role in minimizing this metric by moving loads from underloaded nodes and shutting them down [112].
3.2 Virtual Machines
A virtual machine (VM) is a computer program that acts as if it were a separate computer operating within the main computer. It’s a straightforward approach to run multiple operating systems on the single computer. To make greater use of a powerful server’s resources, it might be divided into multiple smaller VMs. In other words, a virtual machine (VM) is a computing resource that uses software rather than a real computer to run programs and install apps. Despite the fact that they all run on the same host, each virtual machine has its own operating system and operates independently of the others.
Process VMs and system VMs are the two most common categories of virtual machines. The Java Virtual Machine (JVM) is a form of a process virtual machine, as it allows any system to operate Java programs like if they were native to the system.
3.2.1 Purpose of VM
The basic goal of virtual machines is to run various operating systems on the same hardware platform at the very same time. Maintaining different operating systems, such as Windows and Linux, would need two different physical units if not for virtualization. Hardware necessitates a certain amount of physical space, which isn’t always available. Hardware takes a lot of upkeep, repair expenses when it breaks, maintenance costs to maintain it in good shape, and energy expenditures for power and cooling. Virtualization reduces expenses by consolidating all of your operating systems into a virtualized structure, with several instances operating on the same underlying, local hardware, removing the requirement for hardware collection and unnecessary overhead.
Virtual machines are the fundamental components of virtualized computational resources, and they play a key part in the development of any virtual machine application, tool, or environment, both online and off. Here are some examples of how virtual machines are used:
- “Creating and deploying cloud-based apps.
- Trying a new OS, this may include beta versions.
- Creating a new platform to make running dev-test scenarios easier and faster for developers.
- Creating a backup of your current operating system.
- Installing an earlier OS allows you to access virus-infected files or use an old application.
- Using software or apps on platforms for which they were not designed”.
3.2.2 VM Management Technique
VMs can be very efficient in terms of saving time and expense, but they also have their drawbacks. When hosting several VMs and hypervisors, your hard drive will face a substantially larger workload than when using a typical arrangement with one OS per hard disc. VMs can rapidly take up your storage resources, decrease performance because of bottlenecks, and take a lot of space if you don’t have the correct management plan in place. Luckily, there are dependable VM management strategies available to ensure that your virtual environment functions as correctly and successfully as possible.
Here are a few of ways that virtual machines might slow down the server’s performance, as well as how to solve them. The virtual environment is always changing to provide space for new VMs and applications. These configuration modifications, if left unchecked, might result in outages and time-consuming virtual machine sprawl. Configuration modifications can also cause bottlenecks, which might be difficult to spot if you aren’t aware of your previous configuration modifications. You can easily become a victim of sluggish VM performance if you don’t have detailed visibility into configuration information.
The remedy is virtual machine management software that helps you to see and edit custom configuration update templates. Virtual machine management software allows you to keep track of configuration information, troubleshoot that configuration modifications are causing downtime, and monitor previous configuration changes with time.
Additional services will be generated as dependencies on other VMs within the same protection group since VMs are continually expanding and upgrading. Because a defective program might cause problems in its dependencies, diagnosing complex dependencies can be difficult.
VM management software, on the other hand, lets you to use maps and images to view your VM dependencies. Dependency management software can give you a clear picture of the connections between the various services in your virtual system. You can get information about your VMs, application packages, storage indicators, and more through an intuitive design.
3.2.3 Benefits of using VM
Virtual machines offer numerous advantages due to their flexibility and portability, including:
- “Cost savings: You may substantially minimize your physical infrastructure size by running several virtual environments from a single piece of infrastructure. This improves your bottom line by reducing the number of servers you need to manage and saving money on upkeep and electricity.
- Agility and speed: It’s far easier and faster to spin up a VM than it is to set up an entirely new platform for your developers. Virtualization accelerates the execution of dev-test scenarios.
- Lowered downtime: Because virtual machines are so portable and simple to migrate from one hypervisor to the other on a separate system, they’re an excellent backup option if the host falls down suddenly”.
- Scalability: A virtual machine (VM) is a computing resource that, rather than a real computer, executes programs and delivers apps using software. Despite the fact that they all share the same host, each virtual machine has its own operating system and operates independently of the others.
- Security benefits: “As virtual machines can run various OSs, employing a guest OS on a VM lets you to operate software with doubtful security while also protecting your host OS.VMs also improve security forensics, and they’re frequently used to safely research computer viruses by separating them from their host machine”.
3.3 Resource Utilization
The percentage of an employee’s available time that is spent to billable work is referred to as resource utilization. Resource utilization rates indicate how much of your team’s time is spent on billable work and how productive each individual is.
3.3.1 Resource utilization in cloud
Cloud computing is the delivery of numerous services through the Internet. Data storage, servers, databases, networking, and software, among other tools and applications, are among these services. It is presumed that there is a privately held cloud that serves a large number of users. Hundreds or thousands of requests to utilize a given resource through the Internet amass over time from different people all over the world. It is also considered that you have prior knowledge about the requests for using that resource. Through resource pools, allocate a specific quantity of resources to various departments. If you consciously control the resources available per host, you can better regulate the construction of virtual machines. Monitor virtual machine lifecycles so you can swiftly spin them up and down to save cost and make better use of computing resources.
Physical and virtual resources make up cloud resources. Virtualization and provisioning are used to share physical resources amongst many compute requests. Cloud applications get on-demand hardware and software resources. Virtual Machines are rented for scalable computing.
3.3.2 Simple way for improve the Resource utilization in cloud
Capacity and Demand Management: Prioritize high-value task with available resource capability to maximize resource utilization.
Resource Utilization: Make sure that you have the resources you need to achieve your strategic objectives.
Effective resource utilization means getting operations done the right way, in the shortest amount of time, for the least amount of money, and with no waste of resources. The term effectiveness relates to attaining a goal and directing it in the appropriate direction. Strong resource management and resource scheduling techniques are required for efficient resource usage.
3.3.3 Resource management and Resource scheduling
Resource management is a critical component of any cloud platform, and ineffective resource management has a direct impact on performance and costs, as well as an indirect impact on system functioning, since it becomes too costly or inefficient as a result of poor performance. Resource providing, resource identification, resource tracking, resource mapping, resource assignment, resource consolidation, resource modeling, and resource scheduling are some of the resource management strategies. Effective resource management improves service quality while also lowering major resource use. The task of effectively allocating resources to achieve the quality of service needs is becoming extremely difficult. The most basic challenge in deploying Cloud computing services is resource provision [94].
The method of allocating resources across multiple cloud users based on particular norms and regulations of resource utilization in a certain cloud platform is referred to as resource scheduling. The fundamental concept of cloud environment is resource scheduling in resource management.
3.3.4 Optimal resource utilization
The client has a single point of access to the resource due to cloud computing technology, which is deployed on a pay-per-use basis. Although cloud computing has a number of advantages, like pre-defined and abstracted architecture, a totally virtualized platform, dynamic infrastructure, pay-per-use, and no software or hardware installations, the order in which requests are fulfilled is the most important consideration. The resource scheduling develops as a result of this. This resource distribution must be done in a way that maximizes system usage and overall efficiency. Cloud computing is available on demand and is priced according to time constraints, which are usually expressed in minutes or hours. As a result, scheduling should be done in such a manner that the resource is used effectively [95].
Physical machines (PMs) may now be more finely managed because of virtual technology, which allows them to handle many virtual machines (VMs).Different physical resources, including as Processor, memory, bandwidth, and disc storage, can be assigned to each VM.As a result, the whole resource can be multiplexed to maximize its utilization. If required, VMs can be moved as well. The datacenter (DC) is thus formed by the virtualized server cluster in various topology structures [94].
3.4 Problems in Load Balancing
One of the most difficult aspects of cloud computing is load balancing that requires distributing a dynamic workload among numerous nodes to guarantee that no single node is overburdened. It aids in the most efficient use of resources and, as a result, improves system performance. Load balancing is a critical problem in cloud storage. Because the system is too large to spread load in a timely manner, maintaining load information would be very costly. Together with load balancing, there are many other issues to consider, which including resource scheduling, performance evaluation, quality of service management, energy usage, and cloud service availability. Network load balancing presents two fundamental challenges: scalability and network safety.
Scalability: Cloud computing scalability is one of its most attractive characteristics, particularly considering its rapid adoption. Unfortunately, this is also one of load balancing’s most serious flaws. Many balancers can only allocate processes to a small number of nodes, which limits scalability. Balancers will become less efficient with heavy workloads due to a lack of accessible nodes. As a result, a large enough company can require many load balancers. Costs and interoperability may be affected as a result.
Maintaining Network Security: Another major issue among firms as they make the transition to remote work is security. Network load balancing, in general, increases security by lowering the risk of a crash. However, given their new pressure, maintaining security may be a more difficult challenge.
Businesses will have more to safeguard when more web-based programs, such as enterprise resource planning (ERP), are adopted. Smaller businesses may lack the necessary resources to balance and secure these apps. Their IT departments may be overburdened due to a concentration on load-balancing strategies and security flaws.
Several load balancers decrypt traffic before distributing it, which poses a security risk. When a load balancer and web server are located in different data centers, information may be exposed while travelling among them. The complexity of load balancers also leads to vulnerabilities like unsecured administrative interfaces due to inconsistent builds. Some other challenges in load balancing in the cloud are listed as below:
- “Single Point of Failure: Different dynamic load balance methods are developed where some approaches are not disseminated and the central node makes choices about the load balancing. If the central device fails, the entire computer environment will be affected. Therefore, certain distributed methods have to be developed in which a single node does not control the whole computer system.
- Virtual Machine Migration: Virtualization enables multiple VMs to be created on a single physical system. These VMs have various settings and are independent in nature. If a physical system is overcharged, some VMs need to be remotely load-balanced utilizing a VM migration method.
- Heterogeneous Nodes: Researchers speculated about homogeneous nodes during early studies on cloud load balance. In cloud computing, user needs vary constantly, requiring them to run on diverse nodes to efficiently utilize the resources and to minimize response times. Therefore, it is a problem for researchers to develop effective load-balanced methods for the diverse environment”.
- Storage Management: Cloud storage addressed the issue of previous conventional storage solutions requiring personal and hardware administration. The cloud enables users to store data without access issues in a diverse way. Full data replication methods are not particularly effective because of the replication sites’ redundant data storage policy. Partial replication may be adequate, but the availability of data sets may be problematic and the complexity of load-balancing methods increased. Therefore, an effective load-balancing method has to be created that takes account of application distribution and associated data based on a partial replication system.
- “Load-Balancer Scalability: On-demand availability and cloud services scalability enable customers to obtain services fast or swiftly at any time. To make these adjustments efficient, a smart load balancer should consider rapid changes in computational power, storage, system architecture, and so on.
- Geographical Distributed Nodes: In general, cloud data centers are dispersed globally for computer reasons. Spatially dispersed nodes are processed as a single location system in these centers to effectively execute user requests. Some of the load balancing methods is intended for smaller areas in which issues such as network latency, communication delay, distance between distributed computing nodes, distance between user and resources etc. are not taken into account. Knots situated far away are a problem, since they are not suited for this environment. The design of load-balancing algorithms for remote nodes should thus be considered” [42].
3.5 Methodology
3.5.1 Architectural Design
The architecture of your system includes the cloud broker, the VM manager, the programming algorithm, servers and VMs. Cloud includes several data centers that include a network of virtual services that enables users to access and install applications worldwide on demand at competitive prices based on their QoS needs. Each VM has unique capabilities to do various customer-specific QoS duties.
Consumers/Brokers: A task is done in the form of the minimum and maximum frequency resources (MHz) required. Cloud customers or their brokers send service applications to the Cloud from across the globe. It is essential to note that there may be a distinction between cloud users and users of services deployed. For example, a consumer may be a web application business, which offers different workloads depending on the amount of users using the service.
VM Manager: Monitors the availability and use of resources of VMs. It is responsible for supplying new VMs and relocating VMs on actual computers to suit the positioning. If the VM manager has a job and the job requirements, he submits the job requirements and resource statements to the scheduling algorithm.
VMs: According to incoming demands, several VMs may be dynamically started and terminated on a single physical system, giving a flexibility to configure diverse divisions of resources on the same physical machine for varied service needs. Multiple VMs may execute programs on a single physical computer depending on various operating system settings. Workloads may be condensed and idle resources can be converted to low-power mode by dynamically moving VMs between physical machines, turned off or set to run with poor energy efficiency.
The planning algorithm looks for available servers to set up VMs to assign a task according to the job criteria. The SLA must also be taken into consideration in the algorithm. The scheduling algorithm chooses the most energy-efficient option. If the needs of the task cannot be met by all available servers, the scheduling algorithm must inform the VM manager of the power on the right servers. The scheduling algorithm delivers the solution to the VM Manager after reaching a choice. Figure 3.1 illustrates the typical algorithm structure for scheduling.
Fig 3.1 Architectural Design [108]
The cloud computing framework consists of the cloud broker, the VM manager, the algorithm for programming, servers, and VMs. Cloud comprises a few server farms that feature a virtual services system that encourages the user to reach and transmit applications worldwide on demand at competitive cost according to their QoS needs. Each VM has a specific ability to do certain QoS tasks which are monitored by clients. In the cloud, scheduling jobs is a highly important and difficult activity. Modification of the schedule is essential for improvement and also for excellent services. Figure 3.2 shows how the job is scheduled in the cloud network. Tasks are submitted by users, and the data center broker serves as a middleman between tasks and VM. The data center broker identifies the best suitable VM for the job and then assigns the VM to the specific task. Task planning is viewed from two cloud resources views from which customers need to know which cloud computing resources can satisfy their QoS-processing needs and how much more they can pay for the cloud.
The programming involves mapping the tasks to the assets. The main aim is to connect the arrangement of jobs provided by experts to the available VMs with the aim of reducing execution time and operating costs. These current methods have certain drawbacks of increasing runtime and reduced performance. The better programming of the individual job in the cloud is still a problem. Since cloud includes distinct unmistakable assets and costs of completing assignments in the cloud, the scheduling of cloud companies varies entirely from current scheduling methods.
Given that millions of users benefit from the cloud services by submitting their millions of computing jobs to cloud computing, it is extremely important and difficult for the cloud to plan these millions of activities. The primary motivation for task planning is to achieve superior cloud performance in terms of improved performance, load balancing, service quality, cost-effectiveness and optimum operating time. Task scheduling may be seen in two ways – from the point of view of cloud resources, users need to determine which cloud computing resource can satisfy their computer work QoS need and how much they have to pay for the cloud computing resources. Although cloud providers see it as their objective to maximize revenues by providing cloud computing resources, in addition to fulfilling the user’s QoS needs. The cloud scheduling process is completed in three stages known as the discovery or filtering of resources, selection of resources and assignment of tasks. In the discovery of or filtering resource, the data center broker finds the resources accessible in the network system and gathers status information. The target resource in resource selection is chosen according to task and resource needs. The task is assigned to the chosen resource in the task assignment.
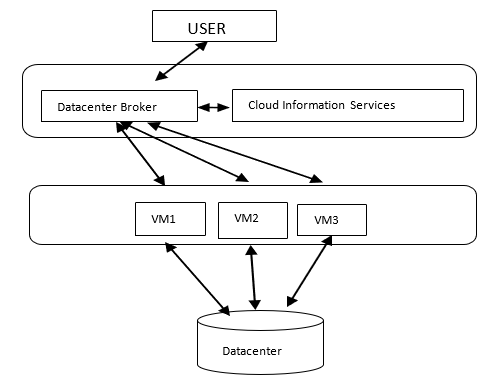
Fig 3.2 Task scheduling in cloud computing framework [109]
The most important entity in cloud computing is the broker who act as an interface between users and cloud service provider for mediating their interactions. “The broker’s responsibility includes maintaining a list of virtual machines (VMs) and the corresponding QoS. User sends the request to the cloud broker and cloud broker further forwards the request to the VM server. After selecting the proper VM that meet the user’s requirement and Service level agreement (SLA), broker binds the task to that particular VM. Fig 3.3 depicts the task scheduling in cloud environment”.
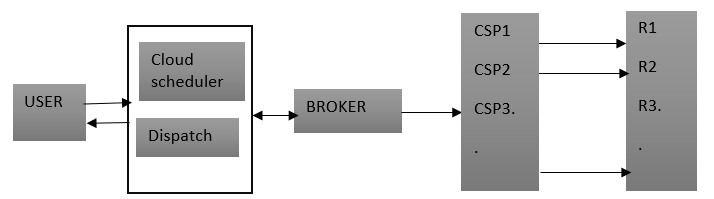
Fig 3.3 Task scheduling in cloud [110]
3.5.2 Existing Heuristic Scheduling Framework
Hyper-Heuristic method offers superior outcomes for difficult planning issues of cloud computer systems compared to the rule-based approach. The complicated planning issues are as comprehensive as NP. A heuristic method illustrated in figure 3.4(a) has its own advantages and disadvantages. For example, optimizing Ant colony takes more time to calculate than other algorithms but provides a better scheduling solution. Scheduling algorithms may be constructed by mixing two or more heuristic algorithms with a rule-based algorithm. Heuristic algorithm integration produces better outcomes than a single heuristic algorithm. In each cycle where Hi is a single heuristic algorithm shown with figure 3.4, a hybrid heuristic algorithm conducts transition, evaluation and determination (b). In a single loop, this requires more calculation than a basic heuristic method.
Hyper-Heuristic is a combination technique of heuristic algorithms [46]. A heuristic algorithm is chosen by employing a low-level heuristic (LLH) selection operator from the heuristic algorithm pool. This kind of algorithm utilizes the heuristic selection and acceptance of a low level operator to choose a heuristic algorithm. One of the heuristic algorithms in the competitor pool will be selected as the heuristic calculation by the heuristic low level selection administrator (LLH). The selected Hyper-Heuristic computation (LLH) is then repeatedly carried out until the end basis is fulfilled. The chosen LLH will develop the response to emphasis by making use of the ability to adjust the rise and enhance the pursuit bearings, which therefore depend on the information provided by the changing identification administrator and the decent variety identification administrator to decide whether to select another LLH or not. This method lowers the working time of the schedule shown in figure 3.4. (c).
3.5.3 Hyper Heuristic Algorithm
- “Set up the parameters
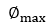
 ; is maximum number of iterations the selected low-level algorithm is to run and
; is maximum number of iterations the selected low-level algorithm is to run and  is the maximum number of iterations for which solutions are not improved
is the maximum number of iterations for which solutions are not improved - Input the scheduling problem; creating the number of data centers, cloudlets and virtual machines.
- Initialize the population of solutions
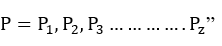
 ”
” - “A heuristic algorithm is randomly selected from candidate pool H which contains GA, PSO, ACO, FCFS, and SJF.
- As termination condition is not satisfied.
- Update the population of solutions P by utilizing appropriate algorithm.
- Improvement Detection operator i.e. F1 = Improvement Detection (P).
- Check whether the results of the selected
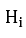
 is improved
is improved - If the results are not improved till
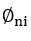
 iterations then return false and select another algorithm from candidate pool.
iterations then return false and select another algorithm from candidate pool. 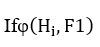
 returns false.
returns false.- Randomly select a new
 .
. - Perturbation operator i.e. P= Perturb (P) reanalyze the solutions.
- End.
- End.
- Output the best so far solution as the final solution”.
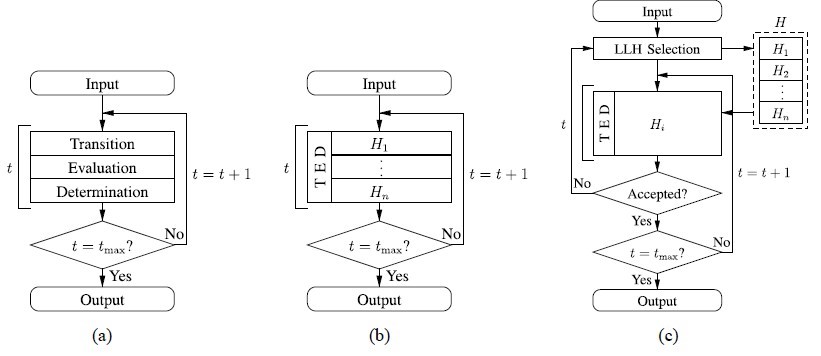
Fig 3.4 (a) Heuristic Algorithm (b) Hybrid-Heuristic Algorithm (c) Hyper-Heuristic Algorithm [46]
3.6 Proposed Algorithm
The suggested method utilizes the idea of load balance to further improve the solution found by the Hyper-Heuristic algorithm. The technique of load balancing ensures system load balancing by estimating the load on every virtual machine and transferring the loads on the basis of overload and under-loaded machine demand and supply values. For the suggested load balancing method it is used to balance loads across Vm’s honey bee optimization algorithm [91].
Load balancing is the process of distributing a distributed system’s overall load among individual nodes in order to ensure that no node is overworked or idle. When particular VMs are busy or perform a lot of work, load balancing in a cloud environment ensures that no VMs are overwhelmed. Load balancing aims to reduce the time it takes for a program to run. It also ensures that the system remains stable. It’s a great backup option in case something goes wrong. The architecture of a basic load balancing system is shown in Figure 3.5.
“Qualitative measures like as performance, use of resources, scalability, response time, fault tolerance and migration time may be enhanced through better load balance in cloud computing. Improving the aforementioned elements ensures excellent customer quality.
Algorithms for load balancing are primarily divided into two; static and dynamic. Static load balancing methods don’t take into account the prior state of the node, and when loads change little, they function well. It is thus not appropriate for the cloud environment. The load balancing technology based on the bee colony algorithm is a dynamic load balancing technology that takes into account the previous node status in the distribution of the load”.
In the first phase, datacenter broker connects with the CIS to gather information about the data center’s resources. Tasks in cloud environments are shown in CloudSim frameworks as clouds. When the cloudlets are reached, the broker will send them to VMs for execution in a datacenter. During task execution, jobs such as cloudlets from overloaded VMs are removed and allocated with loaded VMs for efficient execution if some are idle or perform little work.

Fig 3.5 Basic Load Balancing Architecture [111]
“The Bee Colony algorithm is a swarm-based algorithm based on honey bee colonies’ drilling behavior. The model comprises of scout bees, beekeepers and food. In bee colonies, Scout Bees drill for food and discover a source of food, return to bee hive and conduct a waggle dance. Using waggle dance, other bees in the hive get an idea of the amount of food and the distance from the bee colony. Then foragers follow the scout bees to the location of the bee hive and start harvesting it. The locations of the food sources are chosen randomly by the bees”.
Below table 3.1 mentioned how the cloud environment is mapped to the foraging behavior of honey bee.
Table 3.1 Honey Bee Behavior mapped to the cloud environment
Cloudlet is used in the virtual cloud environment as a honey bee forging behavior in Honey Bee. As Honey Bees pursue food sources, clouds will be allocated to run in VMs. Each VM has distinct job execution capabilities. Some VMs may be overloaded and others underloaded. In this case, a better load balance is needed. In this situation, if a VM is overloaded with several clouds, certain cloudlets are thus removed from that particular VM and are assigned to an underloaded VM.
3.6.1 Hyper Heuristic Algorithm with Load Balancing HHSA_LB


- Initializing the cloudsim library.
- CloudSim.init(no_of_users, calendar, flag);
- String [] candidatepool = {ACO, PSO,GA,FCFS,SJF};
- selected_Candidate = candidatepool[r.nextInt(1)];
- Datacenters, hosts and processing elements list are created by using the specific constructors
- Host host= new Host (host_Id, new RamProvisionerSimple(r), new BwProvisionerSimple(bandwidth), store, pes_list, new VmSchedulerTimeShared(pes_list))
- DataCenter dc = new Datacenter (name, characteristics, new VmAllocationPolicySimple(host_List), storageList)
- Virtual machines and task are created by calling Vm and Cloudlet constructor.
- Vm v1 = new Vm (vm_id, broker_Id, mips, pes_Number, r, bandwidth, s, vmm, new CloudletSchedulerTimeShared ());
- Cloudlet c1 = new Cloudlet (c_id, c_length, pes_No, f_size, o_size, utilizationModel, utilizationModel, utilizationModel);
- For Itr=0 Itr<phinItr++
- SubmitSelectedPoolAlgobroker”(Vmlist)
- “Collections.shuffle(cloudletList);
- SubmitSelectedPoolAlgobroker (cloudletList)
- Cloudsim.startSimulation()
- for v=1 to size of sorted VMList
- for all c=0 to size of CloudletList
- Mapping of cloudlet to the vm is done sendNow(getVmsToDatacentersMap().
- get(vm.getId()), CloudSimTags.CLOUDLET_SUBMIT, cloudlet);
- End for
- End for
- Analyse the parameters for each cloudlet processing on vm.
- Cloudsim.stopSimulation()
- End Loop
- Received the processed cloudlet List and analyse the makespan time parameters.
- Check improvement in makespan time list for the last 4 iterations if improved then continue with rest of iterations
- If not then select the algorithm from candidate pool again
- selected_Candidate = candidatepool[r1.nextInt(2)];
- Forint itr=phinitr<maxiterationsitr++
- Repeat step 8 to 16 again for the rest of iterations
- End loop
- Return the solution with minimum makespan time”.
3.7 RESULTS AND DISCUSSION
In this chapter, the results obtained from the existing algorithms and the proposed algorithms have been discussed and analyzed on various scenarios and compared on the basis of performance parameters makespan time, total execution time, throughput, average response Time, average wait time, total processing time, and total processing cost are all factors to consider. The suggested methods were implemented using Cloudsim and NetBeans IDE, a Cloudsim library that offers a cloud computing simulation environment as well as main classes that describe virtual machines, data centers, users, and applications.
The results of the various proposed algorithms are analyzed and discussed in detail with different number of virtual machines and cloudlets i.e. task. The basic input values taken for the simulation using Cloudsim is shown in the table 3.2.
Table 3.2 Cloudsim Specification for experimental analysis
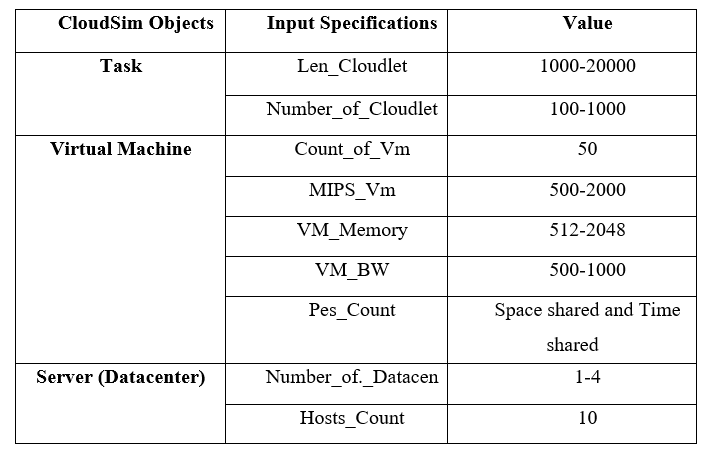
In Table 3.2, Len_Cloudlet is the length of cloudlet(task), Number_of_cloudlets is the total number of tasks available for simulation, Count_of_Vm is the number of virtual machine available for the scheduling of tasks, MIPS_Vm is the number of instructions in millions processed by Virtual machine, VM_Memory is the memory available by virtual machine, VM_BW is the bandwidth available of the virtual machine, Pes_Count is the number of processing elements in the virtual machine, Number_of_Datacenters are the total number of datacenters used in cloud and Hosts_Count is the number of cloud host available on the server.
The proposed algorithms has been analyzed on various input parameters and their performance is compared on the basis of two metrics comprises of Total Processing Cost and Total Execution Time represents in Equation 3.5 and Equation 3.6.The performance evaluation of different metrics is computed under the different sets of workloads using five different ranges of tasks.
The performance parameters used for the result analysis are:
1. Total Processing Cost (TPC)
To accomplish specified set of jobs by procedure, the cost required is Processing Cost.

Where k is number of virtual machines
2. Total Execution Time (TET)
It is the time taken to execute a task. It is the extent of variance between finish time and the execution start time of the task.
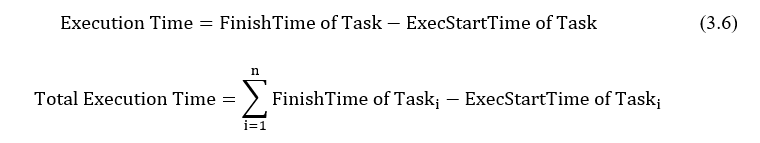
3.7.1 Performance Comparison
The performance of the suggested Load balancing based Hyper heuristic approach was compared to that of the current Hyper heuristic algorithm as well as other heuristic algorithms such as ACO, PSO, and GA algorithm, using two performance metrics: Processing Cost and Execution Time. The performance is assessed using five distinct employment situations, with comparisons made using the Honey Bee optimization-based hyper heuristic method and other heuristic algorithms.
- Performance based on Processing Cost
The results of the suggested algorithm are assessed in this part on the basis of the total cost of processing and compared with other existing heuristic algorithms. The processing cost comparison of methods is shown in Table 3.3.
Cost of processing: The cost of processing is the cost needed to do certain operations using an algorithm.
In this instance, the processing costs for the suggested method are 8975.8 for 500 tasks, which are 12452.28 in the hyper heuristic algorithm, 5 distinct scenarios have been assessed by a changing number of tasks [46]. The comparison with other heuristic methods was also made. The next figure 3.6 demonstrates clearly that the suggested algorithm performs better with regard to cost metrics.
Table 3.3 Result analysis of different workflows for Total Processing Cost
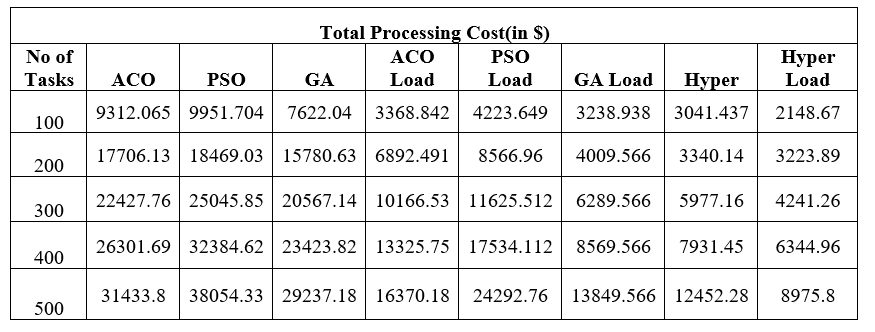
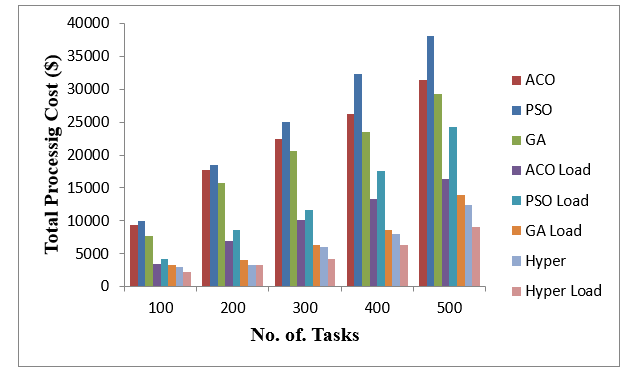
Fig 3.6 Total Processing Cost Comparison
- Performance based on Execution Time
In this section, performance of proposed algorithm is tested based on the Execution Time and is compared with other existing heuristic algorithm. Table 3.4 shows the Execution Time comparison of algorithms.
Table 3.4 Result analysis of different workflows for Total Execution time
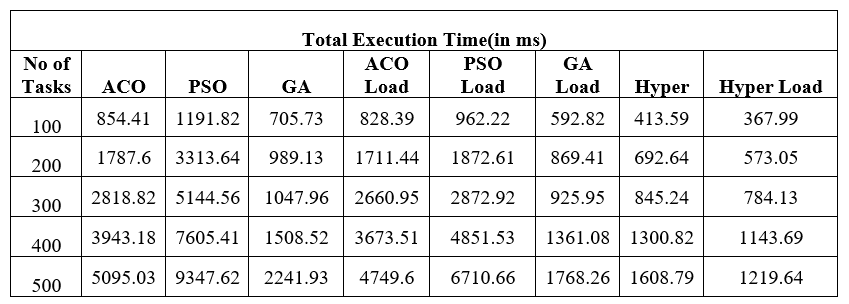
Here, the performance was assessed by a variety of tasks, with the time of execution of the proposed method being 1219.64 milliseconds and in Hyper-Heuristic algorithm is 1608.79 milliseconds for 500 tasks. The comparison with other heuristic methods was also made. The next figure 3.7 clearly demonstrates that the method suggested works better with regard to execution time.
Fig 3.7 Execution time Comparison
3.8 CONCLUSION
Task planning remains one of the major exploration issues under distributed computing conditions. Different heuristic computations such as ACO, PSO and GA are explored in this study. Honey bee-based load balancing is utilized as the suggested method using Hyper-Heuristic. The suggested load balancing method demonstrates improved performance in terms of processing costs and execution time for a large number of clouds.
CHAPTER-4
SLA-AWARE LOAD BALANCING USING RMF IN CLOUD COMPUTING SYSTEMS
4.1 Introduction to SLA
A “Service-Level Agreement (SLA)” is a service provider-client commitment. The service supplier and user agree on certain elements of service – quality, availability, obligations. The most typical component of a SLA is to deliver the services to the client as stipulated in the contract. It defines:
- “The metrics used to measure the level of service provided.
- Remedies or penalties resulting from failure to meet the promised service level expectations”.
It is an essential component of any deal with technology vendors. For example, Internet service providers may often include service level contracts with consumers to specify the level of service they provide in simple English terms. SLAs are usually between businesses and external providers, but may also be between two divisions inside a firm.
In this instance, SLA usually has a technical definition between failures, average repair or a mid-term recovery time (MTTR), which party is accountable for reporting defects or costs, responsibility of different data rates, output, jitter or similar quantifiable characteristics. The Service Level Agreement contains:
- “Detailed service overview
- Speed of service delivery
- Plan for performance monitoring
- Description of the reporting procedure
- List of penalties that will be applied in case of agreement violations”
Constraints
4.1.1 SLA in cloud environment
SLA serves as a future basis for the supply and monitoring of cloud computing services. Consumers need SLAs to define their quality of service, security and performance failure backup needs. Consumers are nevertheless allowed to select from various service providers. Standard SLAs are often provided by cloud computing companies. Service quality relies on understanding what customers demand and how suppliers provide.
The SLA template usually includes numerous factors, such as cloud resources (physical memory, main memory, processor speed, etc.) and characteristics (availability, response time etc.). An SLA shows what the customer and service provider aim to accomplish by cooperating with each other and defines the parties’ responsibilities, anticipated performance levels and outcomes of collaboration.
An SLA normally has a specified period given in the document. The services the supplier promises to provide are typically specified in depth in order to prevent misunderstandings, including performance monitoring, evaluation and trouble sheeting processes. For a good agreement, the following components are necessary:
- Document overview:This first section sets forth the basics of the agreement, including the parties involved, the start date, and a general introduction of the services provided.
- Strategic goals:Description of the agreed purpose and objectives.
- Description of services:The SLA needs detailed descriptions of every service offered under all possible circumstances, including the turnaround times. Service definitions should include how the services are delivered, whether maintenance service is offered, what the hours of operation are, where dependencies exist, an outline of the processes, and a list of all technology and applications used.
- “Exclusions: Specific services that are not offered should also be clearly defined to avoid confusion and eliminate room for assumptions from other parties.
- Service performance:Performance measurement metrics and performance levels are defined. The client and service provider should agree on a list of all the metrics they will use to measure the provider’s service levels.
- Redressing:Compensation or payment should be defined if a provider cannot properly fulfill their SLA.
- Stakeholders: Clearly defines the parties involved in the agreement and establishes their responsibilities.
- Security:All security measures that the service provider will take are defined”. “Typically, this includes the drafting and consensus on antipoaching, IT security, and nondisclosure agreements.
- Risk management and disaster recovery: Risk management processes and a disaster recovery plan are established and communicated.
- Service tracking and reporting:This section defines the reporting structure, tracking intervals, and stakeholders involved in the agreement.
- Periodic review and change processes:The SLA and all established key performance indicators (KPIs) should be regularly reviewed. This process is defined as well as the appropriate process for making changes.
- Termination process:The SLA should define the circumstances under which the agreement can be terminated or will expire. The notice period from either side should also be established”.
Finally, all stakeholders and authorized participants from both parties must sign the document to approve every detail and process.
4.1.2 CPU based SLA
The CPU SLA function allows users to restrict the utilization of a virtual machine in CPU. Computer capability metrics (i.e. CPU) of the provider are especially vulnerable to inappropriate use. For example, When an agreed-upon metric in the SLA determines that the number of processors assigned to a given service must be more or equal, the provider must maintain this assignment throughout the service’s performance, even if the service does not use all of the assigned capacity at some points (i.e. the provider is forced to statically overprovision processors to the service to avoid SLA violations). It’s worth noting that idle resources might be temporarily transferred to another service, boosting the provider’s utilization and profit.
[93].
Multiple service-level agreements with associated service-level goals may include numerous service-level metrics. In IT services management, a call center or a service desk is a typical example. In these situations, the generally accepted metrics include:
- “Abandonment Rate: Percentage of calls abandoned while waiting to be answered.
- ASA Average time (usually in seconds) it takes for a call to be answered by the service desk., Resolution time: The time it takes for an issue to be resolved once logged by the service provider”.
- “Error rate: The percentage of errors in a service, such as coding errors and missed deadlines.
- TSF (Time Service Factor): Percentage of calls answered within a definite timeframe, e.g., 80% in 20 seconds.
- FCR (First-Call Resolution): A metric that measures a contact center’s ability for its agents to resolve a customer’s inquiry or problem on the first call or contact.
- TAT Turn-Around-Time): Time is taken to complete a particular task.
- TRT (Total Resolution Time): Total time is taken to complete a particular task.
- MTTR (Mean Time To Recover): Time is taken to recover after an outage of service.
- Security: For example, the amount of unrevealed vulnerabilities. If an incident happens, service providers should show that preventative steps have been implemented.
- Uptime: It is also a popular measure for shared hosting, virtual private servers and dedicated servers. Standard contracts contain network uptime %, power uptime, number of planned repair windows, etc. When applied to IT services, many SLAs follow the ITIL standards”.
4.2 SLA Violation
An SLA specifies all service level targets (SLOs) and established quality of service parameters (QoS) and demonstrates the responsibilities and commitments of every party, including the performance and penalties to be imposed in the event of an infringement by SLA [75]. SLA infringement happens when one or more SLOs are unsatisfied. There are many causes for SLA infringements, such as aggressive consolidation, incorrect VM size or inadequate elasticity solutions. Therefore, contemporary elasticity should be offered to VMs by public, private and hybrid cloud providers [74].
A logical answer to every breach is a punishment. An SLA penalty varies on company and sector. This is the two most frequent kinds of SLA penalties.
- Financial penalty
- Service credit
Financial Penalty: This type of penalty compels a vendor to compensate a client for damages equal to those specified in the contract. The amount will be determined by the severity of the violation and the degree of the harm, and it may not be sufficient to completely repay a client for the eCommerce service or eCommerce assistance.
“License extension or support: It requires the vendor to extend the license term or offer additional customer support without charge. This could include development and maintenance.
Service Credit: In this case, a service provider will have to provide a customer with complimentary services for a specific time. To avoid any confusion or misunderstanding between the two parties in SLA violation, such penalties must be clearly articulated in the agreement. Otherwise, they won’t be legitimate.
- Service availability: It includes factors such as network uptime, data center resources, and database availability. Penalties should be added as deterrents against service downtime, which could negatively affect the business.
- Service quality: It involves performance guarantee, the number of errors allowed in a product or service, process gaps, and other issues that relate to quality”.
These punishments must be stated or will not be enforced in the SLA language. Moreover, some clients may not believe that the penalty for service credit or license extension is sufficient recompense. They may question the benefit of continuing to get services from the provider which cannot satisfy their quality standards.
Therefore, a mix of penalties and incentives, such as a monetary bonus, may be worth considering for more than acceptable performance.
4.2.1 SLA Violation Prediction and Handling
The Service Level Management (SLM) is the cloud resources and services management methodology. In cloud computing, the efficient cloud service is regarded to provide sufficient service as described in the SLA and to address the problems promptly for customer satisfaction.
The selection of a SLA prediction algorithm with suitable control parameters is an essential part of the management and avoidance of SLAs by service providers. Failure to respect the established QoS standard leads in violation fines and harm to the reputation of a supplier. By adopting more formal quantitative prevention techniques and choosing an optimum parameter for the associated approach, a provider may minimize the probability of a service breach. Therefore, it is essential that the service provider choose the right QoS prediction technique, depending on its forecast accuracy at various time intervals to control the risk of SLA violations and to prevent violation penalties [36].
Since business needs are prone to change, a frequent revision of the SLA is essential. It will assist to make the agreement consistent with the service level goals of the company. The SLA should be updated if the following changes take place:
- “A company’s requirements
- Workload volume
- Customer’s needs
- Processes and tools
The contract should have a detailed plan for its modification, including change frequency, change procedures, and change log.
- SLA Calculation
SLA assessment and calculation determine a level of compliance with the agreement. There are many tools for SLA calculation available on the internet.
- SLA uptime
Uptime is the amount of time the service is available. Depending on the type of service, a vendor should provide minimum uptime relevant to the average customer’s demand. Usually, a high uptime is critical for websites, online services, or web-based providers as their business relies on its accessibility.
- Incident and SLA violations
This calculation helps determine the extent of an SLA breach and the penalty level foreseen by the contract. The tools usually calculate a downtime period during which service wasn’t available, compare it to SLA terms and identify the extent of the violation.
- SLA credit
If a service provider fails to meet the customer’s expectations outlined in the SLA, a service credit or other type of penalty must be given as a form of compensation. A percentage of credit depends directly on the downtime period, which exceeded its norm indicated in a contract.
Service level management is the process of managing SLAs that helps companies to define, document, monitor, measure, report, and review the performance of the provided services. The professional SLA management services should include:
- Setting realistic conditions that a service provider can ensure.
- Meeting the needs and requirements of the clients.
- Establishing the right metrics for evaluating the performance of the services.
- Ensuring compliance with the terms and conditions agreed with the clients.
- Avoiding any violations of SLA terms and conditions”.
An SLA is a preventive means to establish a transparent relationship between both parties involved and build relationships in the cooperation. Such a document is fundamental to a successful collaboration between a client and a service provider.
4.3 Machine learning based prediction of SLA violation
Cloud computing has opened the path for consumers to use virtual Internet computer resources. This technology enables cloud providers (CPs) effectively use resources and earn more revenue. However, the QoS for customers relies on the resources provided. A CP may trade in any infrastructure, including processors, memory and Internet connectivity. Despite many research in cloud computing literature, resource management in multiservice settings is still in its infancy. In particular, important problems such as customer satisfaction integration, QoS provisioning and the allocation of adaptive resources policies have not been addressed yet.
In contrast to previous contributions, [76] emphasized the integration of the above-mentioned problems with a view to preventing a breach of SLA while optimizing the profit from the CP under different cloud circumstances. In [76], a CP employs virtual machines (VMs) to do customer tasks, with customer payments amortizing the cost of renting VMs. The CP manages the collection of VMs in the cloud environment. In particular, [76] presented a multi-service resource management method based on a Reinforcement Learning (RL) model. The model continuously optimizes the profit for the CP. The Admissions Control Policy combines the modification of the provided number of VMs for each class of customers (RAC). The method involves adapting the resources of the CP to meet demand blocking probability restrictions utilizing the pricing parameter to fulfill QoS demand.
4.4 Methodology
“A new SLA-Aware Risk Management Framework (SA-RMF) is proposed in this work. The SA-RMF combines five modules as shown in Fig 4.1 and this is utilized for solving discovery and reduction of SLA violation. The following are the five modules in SA-RMF.
- Module 1: Dynamic Threshold Formation (DTF)
- Module 2: Observing Runtime QoS (ORQoS)
- Module 3: Hybrid Approach based QoS prediction (HAQoS)
- Module 4: Risk Identification (RI)
- Module 5: Risk Management (RM)”.
In the following subsections, the functions of each SA-RMF module are clarified.
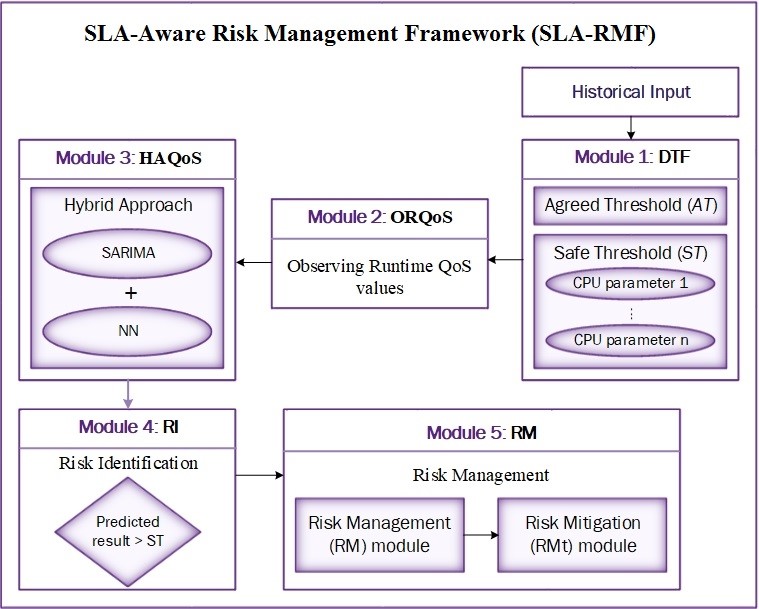
Fig 4.1 Proposed SLA-Aware Risk Management Framework [75]
4.4.1 Module 1: DFT
As seen in Figure 4. 1 DFT is the first structural board of the RMF-SLA. This takes SLO’s QoS values from the client to the cloud provider and sets two thresholds to evaluate and manage breaches. These two thresholds are the Agreed Threshold (AT) and Safe Threshold (ST).
- Agreed Threshold (AT)
In SLA, this threshold value is determined by mutual agreement between customers and providers. While SLAs are being negotiated, both accept specific thresholds for each QoS and SLO parameter. A service provider that refuses to comply with the specified QoS requirements shall violate the service. This is accountable for the infringement fines.
- Safe threshold (ST)
In order to prevent any possible service breaches and fines, it is being suggested that a business should establish a safe threshold (ST) lesser than the agreed threshold (AT). It is a dynamic threshold, and when a QoS operating time passes or exceeds that threshold, it warns of possible infringements of SLA and invokes Module 5, RM to take the measures to avoid the infringement. ST is the most important item to anticipate a potential SLA breach, however many works have taken up this safe threshold, which may lead to a misinterpretation. To address this issue, a new criterion for producing ST is suggested in this study.
In this context, ST must be generated for each SLO in SLA. The common CPU characteristics associated with that particular SLO are evaluated here for the generation of STs that assist to forecast SLA violations indirectly. For instance, in this work the CPU use time is taken as the SLO. The availability, response time and latency are the typical CPU characteristics linked to the use time of the SLO-CPU. Availability implies the potential that a machine can function at a certain moment, i.e. the amount of time a device actually works as a proportion of its total duration.
The response time is the total time required to reply to a service request. Latency is a temporal delay between the cause and effect of some physical system change. The aforementioned definitions show that the availability should be high and the response time and latency should be low if there is no possibility of a SLA violation. These CPU characteristics are utilized to generate ST, which is shown for the SLO-CPU use period in Equation 4.1.
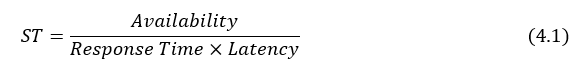
The CPU parameters may get varied according to the SLO which means the provider may consider multiple or less no. of common CPU parameters in the ST generation process.
4.4.2 Module 2: ORQoS
ORQoS is the SA-RMF’s second module that administers the dynamic QoS parameters in the SLA for each SLO. Then the QoS runtime values which are obtained were passed to Module 3-HAQoS whereas the SLOs’ QoS values will be determined in the adjacent future.
4.4.3 Module 3: HAQoS
This is the third module of the SA-RMF that predicts the usage of resources by users for every SLO. This module uses an adequate estimate technique for each SLO to calculate the future worth of the user’s resources based on its use history. The selection of an appropriate instrument for prediction plays an important part in decision making.
Here, the hybrid approach [25] is used to optimally forecast QoS values. The basic structure of Hybrid Approach is shown in Fig4.2 and is accessible in sequence of PCA and balance methods SARIMA and NN models.
The following are the main stages towards the QoS forecast. First, a huge user history database is generated. The selection of the explicative variables is subsequently made, which are the QoS parameters of each SLO. The SARIMA model is initially employed as an alternative linear predictor to estimate the explanatory factors for future values. The aspect of performance data is decreased by balancing methods and main component analysis, which is referred to as PCA + BAL in Figure 4.2.
Instead, the first NN (NN1) is utilized to capture non-linear data relationships for each anticipated variable. In order to guarantee efficiency of generalization, the input data dimension must be decreased once again. A secondary NN (NN2) may then be used to estimate the QoS values based on values of previous QoS parameters and results of the previous stage. By loading predicted outputs into variable data, the multiple step forward estimates are accomplished iteratively.
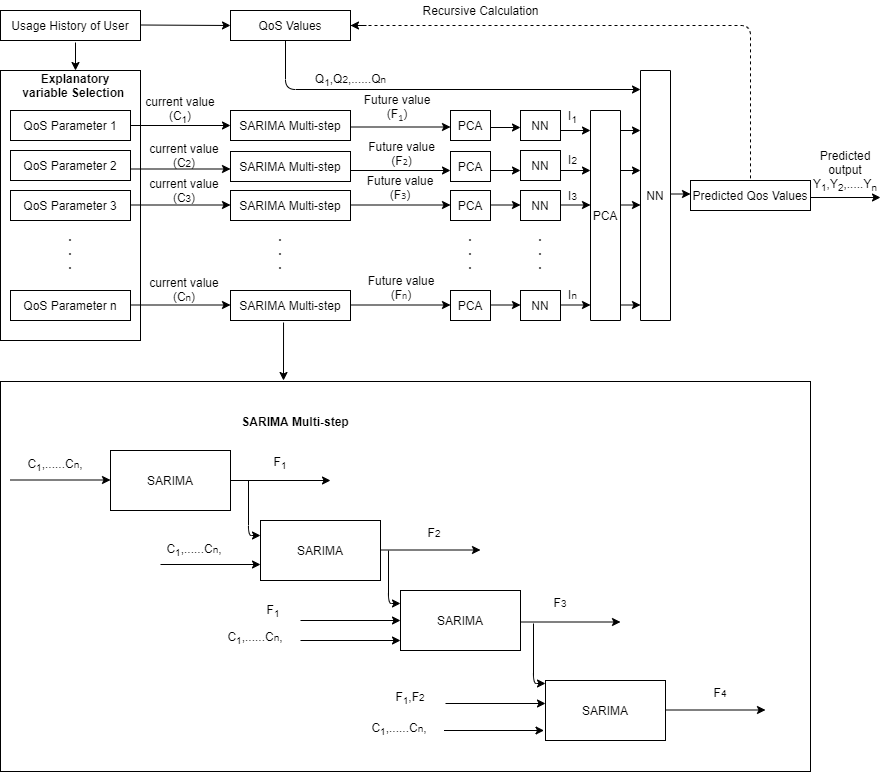
Fig 4.2 Structure of the Hybrid Approach [25]
The model mainly incorporates four associated linear predictors, one step ahead to produce a series of predictions. When the explanatory variables are compiled for the first step (6 hours ahead), they are used as inputs to the two-step forward forecast (12-hours ahead). This cycle is repeated before the explanatory variables for the next 24 hours are forecasted. The same recursive technique is used for predicting QoS values, using prior QoS value estimates as extra input data for further forecasts before 24-hour prediction.
ORQoS continually inputs the value of the SLOs in prior time intervals to HAQoS to improve the accuracy of the prediction output. The pseudo code for HAQoS is explained as follows:
for (x = start value; x <= end value; x++)
if (ORQoS is empty)
input[x] = previous_observation[x];
else
input[x] = ORQoS[x] + previous_observation[x];
Predicted_output = Prediction_algorithm(input);
To estimate the QoS value prediction by taking the relative value of the previous QoS observation values, this is represented in the following equation:
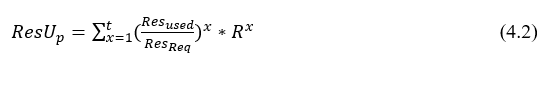

4.4.3.1 SARIMA model overview
The SARIMA model is a classic analytical method used for the estimate of future values as a linearly construct of previous data. This is an enhancement in Box and Jenkins’ Autoregressive Integrated Moving Average (ARIMA), which are used for the regular activities to manage time series outcomes. ARIMA is a model for predictive analysis that utilizes time series data to either better explain data collection or anticipate future trends. Since the QoS values vary regularly, this study is based on the SARIMA model. Seasonal Autoregressive Integrated Moving Average or SARIMA is an enhancement to ARIMA that specifically handles uniform, seasonal time series data. It includes three new parameters for the seasonal component of the series to define the auto regression (AR), differentiation (I), and moving average (MA) and an extra seasonal parameter. A seasonal ARIMA model consists of extra seasonal conditions in ARIMA. The seasonal portion of the model consists of words that are quite similar to the non-seasonal parts of the model, but include retrospective changes throughout the season. ARIMA is available as SARIMA (p, d, q)(P, D, Q)s. The non-seasonal components of the model are stated in lesser cases, the auto regression variable is specified as p, and the difference parameter is shown as d and the average moving parameter (q). The seasonal parts of the model are written in upper cases and are shown as s the number of periods each season. The method of obtaining the SARIMA model may be summarized in four phases: description, analysis, assessment, prediction [25].
- Description: Preliminary values for the autoregressive order P, divergence order d, and moving mean order q are determined as well as seasonal parameters P, D and Q. The first stage is to be determined. The autocorrelation function (ACF) and the partial autocorrelation function are the main components (PACF). In time series analysis and prediction, automotive correlation and partial autocorrelation charts are extensively utilized. Partial autocorrelation (PACF) and autocorrelation (ACF) functions in the SARIMA model for both the seasonal and non-seasonal selection. Self-correlation may also be called a lagging correlation or a serial correlation, because it examines the connection between the present value of a variable and its previous values. Autocorrelation and partial autocorrelation are metrics for the connection of current and previous series values which previous series value are more helpful for the prediction of future values.
- Analytical testing: The parameters and related standard errors can be determined using statistical approaches once the model has been partially constructed.
- Valuation: The evaluation of predicted values and model comparisons are usually included in this stage. The standardized estimated coefficients should behave as an independent and identically distributed sequence with mean zero and variance one if the framework fits properly. And a diagnostic test to verify appropriateness of the residual pattern is also performed in this stage.
- Prediction: Predicting future results, based on the historical evidence. After selected a model and calculated all of the parameters, use it to forecast future values.
4.4.3.2 Overview of Neural Network model
A neural network model (NN) is affected by the perception of the data by the human brain. It is extensively utilized in many areas because to its great generalizing capabilities such as picture recognition, illness detection, energy prices, demand forecast as well as company locations. A NN is described as a computer system consisting of many basic but highly linked components or nodes called ‘neurons’ which are arranged in layers utilizing dynamic state reactions to external inputs and process information. The main task of a neural network is to convert the input into a meaningful output. All neurons affect each other in a neural network, and thus are all linked. The network can recognize and monitor every element of the data set in hand and the possible connection between the various data sections. This is how neural networks can discover very complicated patterns in huge data quantities. The network concept used in this study consists of a single input layer, one output layer and one or more secret or hidden layers. The increasing layer comprises of neuron modules. Each neuron is connected to all previous units of the layer. In the neural network, the flow of data is described in two ways:
- Feed forward Networks:The signals in this model only go in one direction to the output layer. The input layer and the single output layer of the feedforward networks are zero or many hidden layers. They are extensively employed in the identification of designs.
- Feedback Networks:This approach uses the recurrent or interactive networks to process the input sequence in their internal state (memory). In them, signals may flow through the network’s hidden layer/s in both directions. Typically they are utilized in time series and sequential activities.
The inputs was multiplied by weights and then applied to bias, and via a linear process, the effects continue which is shown in the following equation [96]. The process of learning is iterative, during the training phase.

The aims and inputs are added into the network and the biases and weights are changed over and over again until the defects are reduced between the output and the destination value in a specified tolerance criterion. The trained model is tested by ensuring that it produces the right or wrong output. The design of the NN comprises of an individual input layer with 11 neurons, a single output layer along with one neuron, and two hidden layers with each 8 neurons, each with the sigmoid (1/1+e-x) activation function in all layers. The evaluation and experiment [25] determines the quantity of hidden neurons and layers in each layer. The primary strength of machine algorithms is their capacity to learn and improve the prediction of output at all times.
4.4.3.3 Principal Component Analysis (PCA) and balancing
Hybrid solution that integrates SARIMA with NNs underrepresented. When exposed to imbalanced data, standard learning methods have biased the models in the direction of a more popular scenario, which may deteriorate efficiency. In this instance, two preprocessing methods are applied: balancing and principal component analysis (PCA). PCA lowers to a restricted range of uncorrelated variables a wide group of connected variables with most sample knowledge maintained. A common approach used for imbalanced data, using re-sampling methods, overcomes the unbalanced issue. It thus affects data distribution and equals the count of rare, frequent scenarios [25]. The main component analysis, PCA is a statistical process that allows for a smaller collection of summary indices, which can be seen and studied easier, to summarize the substance of information in big data tables. Using PCA, correlations between data points may be identified. Today, one of the most prominent multivariate statistical methods is main component analysis. It is a frequently used technique in the fields of pattern recognition and signal processing, and under the general term of factor analysis is a statistical method. The objective is to extract essential information from the data and to represent it as a collection of summary indexes termed the main components.
4.4.4 Module 4: RI
RI is responsible for comparing HAQoS data with the ST value generated in Module 1. Whether HAQoS values are achieved or exceed the ST value, Module 5-RM allows you to avoid future SLA infringements.
4.4.5 Module 5: RM
As previously stated, RM is triggered when RI agrees on the likelihood of a SLA breach. RM measures till the severity of the possible SLA breach has been triggered and determines how it can be managed. In order to take appropriate steps to minimize the likelihood of SLA breaches, the RM utilizes three elements – the risk management of the supplier, the customer confidence and the purchase history. As shown in Figure 4.3, RM comprises of 2 components [75], 1) Risk Estimation Unit, 2) Risk Mitigation Unit (RMt).
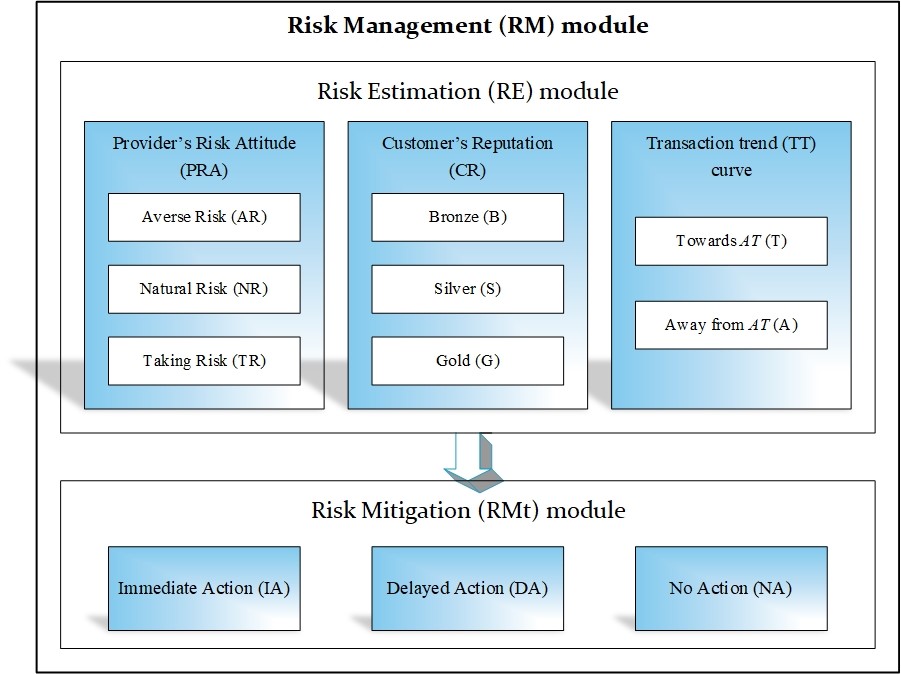
Fig 4.3 Working of RM module in SA-RMF [75]
- RE module: A possible presence of a SLA violation must be assessed. Subjective is the meaning for this word risk and management framework, and the following three inputs are evaluated in the RE module to determine the scale of the risk from either the supplier’s subjective perspective:
- Risk attitude (PRA) of the Provider speaks for its ability to deal with the risk. Three kinds of PRA-area risk (AR), natural risk (NR), or risk management (TR). A supplier with an anticipated risk behavior hesitates to take the possibility (for allowing a SLA breach) compared to a supplier comprising of a risk/normal risk.
- Reputation of the customer (CR) calculating the likelihood of a SLA breach: The significance of efficiency or confidence that a business attaches to a customer to fulfill the SLA conditions is recognized. A reputation of a user indicates the customer’s adherence to original SLAs and is expressed as bronze (B), gold (G) or silver (S). The integrity of the User is an input of the RE module, since if a supplier likes a customer strongly; the provider takes immediate measures to reduce the risk of a SLA violation when compared to the bronze rating.
- Transaction trend (TT) curve beyond the future time period is the third input of a RE module that shows the consumer’s SLO uses over time in the future. It shows the overall usage of resources by the user over time (from HAQoS) as well as the use of maps versus the ST and AT values. If this TT curve overcomes ST, it may go to either AT (T) or AT (A). The RE module uses the TT curve route to determine the potential of a SLA violation and to assess the actions needed to reduce risk.
- RMt module: As stated above, the RE module determines the likelihood of a possible SLA violation with regard to linked inputs. Measures are recommended by the RMt module to control the risk. The suggested actions are assessed using the Fuzzy Inference System (FIS). When assessing a risk of violation as high, RMt recommends that the service provider should take urgent action. After taking this step, the service provider stops accepting new requests. To prevent breaches of service, sufficient resources are provided in a short period. RMt should choose a delayed action on the basis of the likelihood of a violation. It is considered that the supplier accepts the risks but it controls the issue in order to take necessary measures over a certain length of time.
4.5 RESULT AND DISCUSSION
To implement the forecasting of QoS, monitoring SLAs and to eliminate potential violations, Python Programming and Eclipse IDE is used. The proposed work is about how a process assigned to a Physical Machine (PM) is load balanced without violation of SLA. And how it handles the SLA violation by predicting it earlier. For performing this task, CPU time is considered. So when a process is given to a PM, CPU time is allocated to that job and allowed to execute it. It is maintained to be load balanced and SLA violation prohibited.
This work generally gets the processes executed in the local host as input and analyzes the CPU time taken for each process running currently. Using this detail, it also predicts the CPU time needed for processes in future. So it will continue to load the processes continuously for 10 mins time and again reset it for next cycle.
So the overview of the work is to predict the jobs needs to be executed in near future and if any job is predicted to be arrived which cannot be accommodate by the current VM, it would be switched to the next PM.
In order to enforce SA-RMF, it is first necessary to establish a SLA between the client and the service provider. The processor is used as a SLO and tests are necessary to predetermine potential SLA violations proactively. The first SA-RMF module is DTF, which defines the SLO threshold values. The next two phases of the SA-RMF are ORQoS and HAQoS. HAQoS employs a hybrid method for predicting the QoS values in the future. This hybrid technique is tested with 3 existing predictive approaches known as the Automotive Regressive Integrated Moving Average (ARIMA) [75], Neural Networks (NN) and Seasonal Integrated Route Move Average (SARIMA) [25] for measuring the forecast accuracy. Fig 4.4 shows the confusion matrix which consists of predicted label and true label of the proposed work.

Fig 4.4 Confusion Matrix
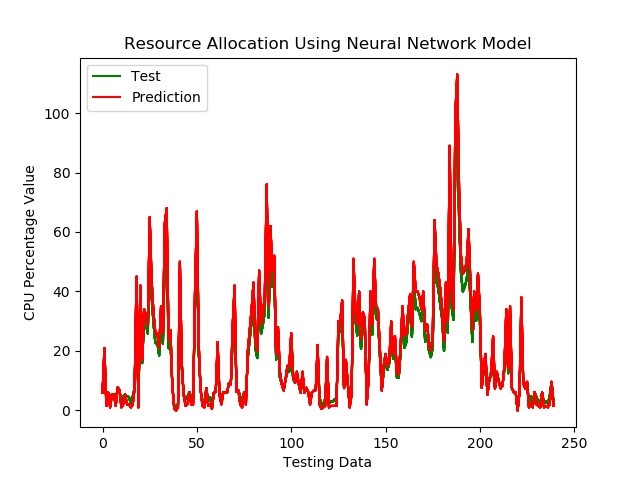
Fig 4.5 Resource Allocation Prediction outputs for Neural Network Model
Fig 4.5 shows the resource allocation prediction output for neural network model. From this figure, the predicted QoS values of neural network higher than the observed data. That means the need of actual CPU usage is less but the predicted CPU usage value is high in the neural network model. Hence the prediction accuracy of neural network is low.
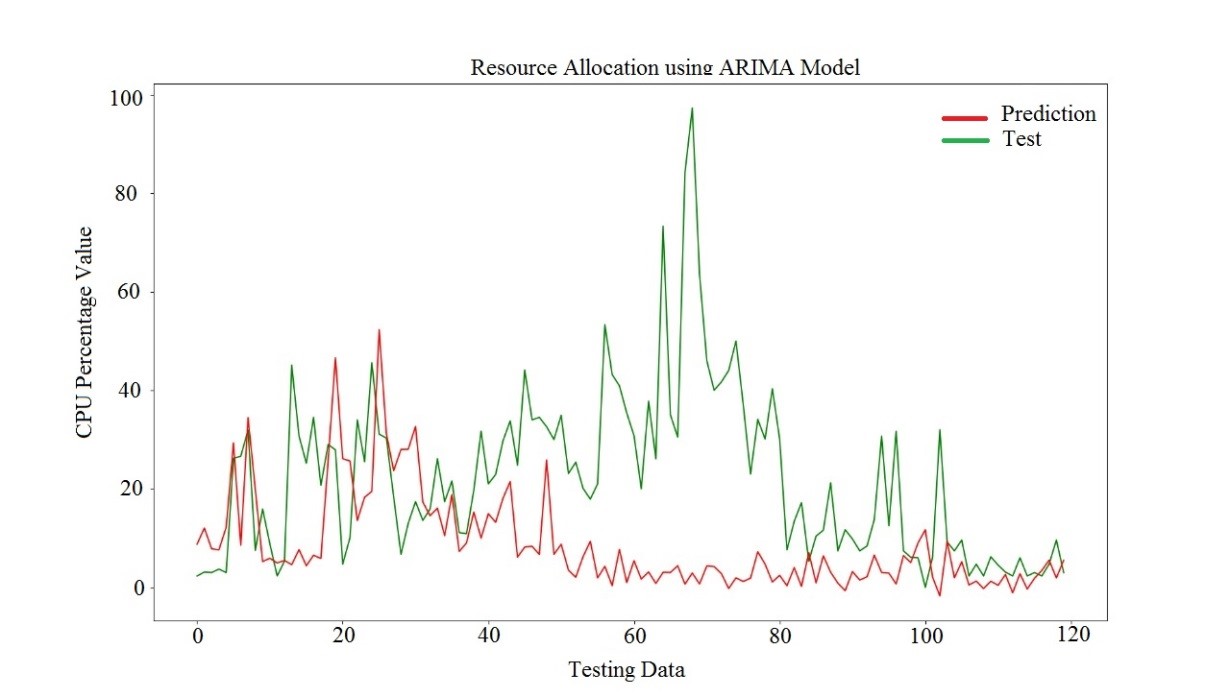
Fig 4.6 Resource Allocation Prediction outputs for ARIMA Model
Resource allocation prediction output for ARIMA model is shown in the fig 4.6. The predicted QoS values are lesser than the observed data in the ARIMA model. It provides poor prediction values hence the prediction accuracy of ARIMA is poor. There are drastic difference in the prediction values and the actual value.
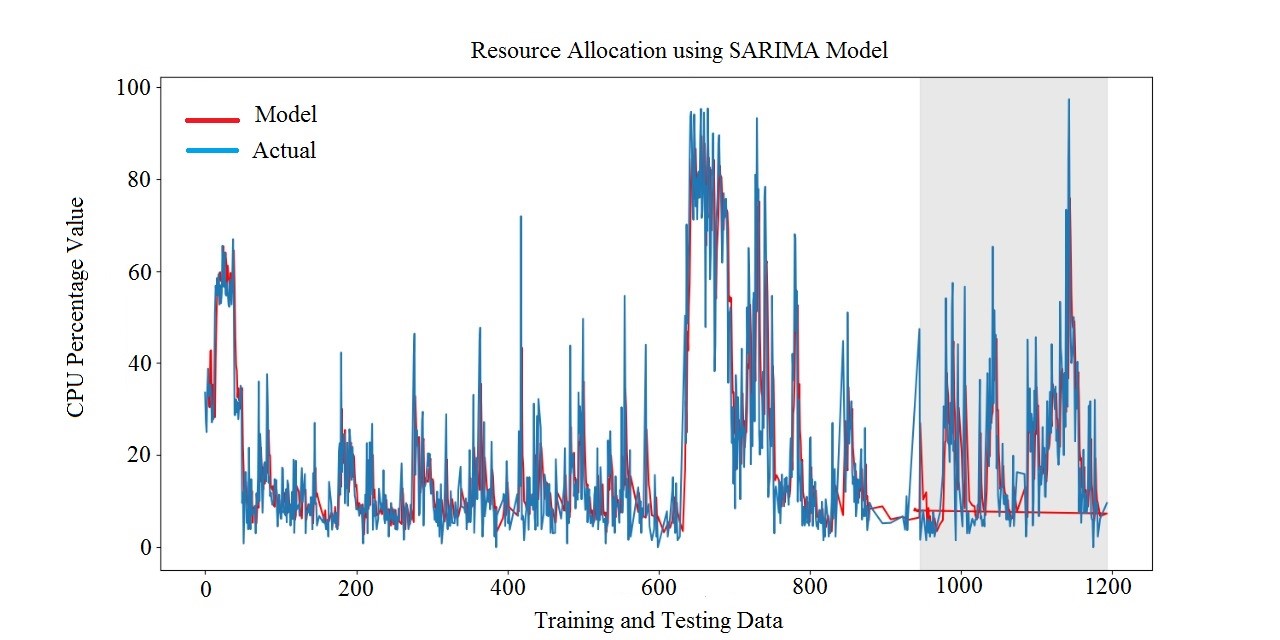
Fig 4.7 Resource Allocation Prediction outputs for SARIMA Model
Fig 4.7 shows the resource allocation prediction output for the SARIMA model in which the predicted QoS CPU values are not match with the actual observed values. It produces the poor accuracy report.
Fig 4.8 shows the resource allocation prediction outputs for hybrid model. The results show that the predicted QoS values of Hybrid approach exactly match with the observed data that means hybrid approach have high accuracy.
Many existing systems have proposed a risk management framework for SLA violation abatement. Obviously this work is better than any other technique because they used ARIMA technique for predicting QoS values and this work used Hybrid approach
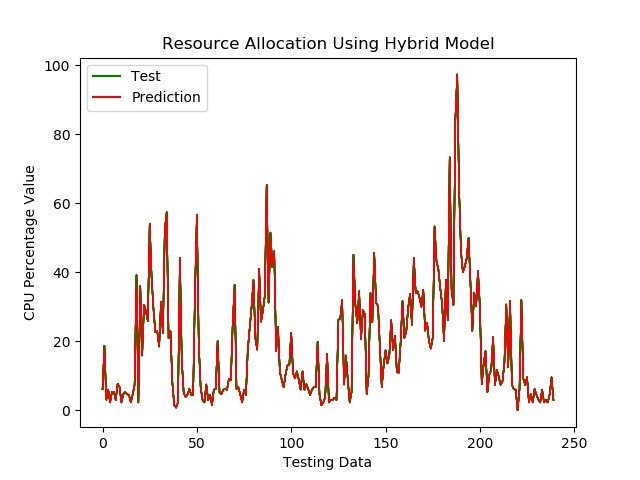
Fig 4.8 Resource Allocation Prediction outputs for Hybrid Model
Also, they only assumed the threshold values which are described in module 1. It should be calculated keenly because it is used in risk identification part but they have not performed this calculation.
4.6 CONCLUSION
The primary agreement established in the cloud computing environment between a service provider and a user is called SLA. It is a difficult job to prevent SLA breaches and fines via improved cloud SLA management. In this study, an efficient load balancing SLA-Aware Risk Management Framework (SA-RMF) is suggested in advance to anticipate and minimize SLA violations. The SLA is handled by the service provider and the SLA violation is prevented by using the SA-RMF, which predicts QoS, identifies possible SLA breaches and proposes the most likely option for preventing violations. In future work on predicting potential SLA breaches, the hidden connections between SLOs will be addressed.
CHAPTER-5
ANALYSIS OF HYPER HEURISTIC SCHEDULING ALGORITHM AND SLA-AWARE RISK MANAGEMENT FRAMEWORK IN CLOUD COMPUTING SYSTEMS
5.1 Introduction
This whole thesis study offered two methods for improved cloud load balance. In the first approach, the Honey bee load balancing is utilized as the suggested algorithm using Hyper-Heuristic. The suggested method anticipates the whole adjusted load to be achieved cross-sectional on virtual machines to minimize the make-up time. The suggested method offers balanced scheduling solutions via the use of the honey bee load balancing and improvement operator to determine which lower-level heuristic solutions will be used. The results of the suggested algorithm of task planning are linked to current heuristic planning methods.
In the second approach, a new SLA-Aware Risk Management Framework is proposed to address the SLA violations issue (SA-RMF). This novel method is described in the following based on CPU settings for efficient dynamic threshold generation. By utilizing SA-RMF Hybrid Approach, a higher quality of service (QoS) prediction is obtained. Experiments show and verify the suitability of the proposed solution, helping cloud providers to minimize future service breaches and repercussions.
Both methods provide an efficient load balance in the cloud environment. In order to analyze the performance of the projects, the two suggested algorithms are compared with other current works.
5.2 Efficiency Analysis of Honey Bee optimized Hyper-Heuristic algorithm
“We compared the evaluation analysis of proposed Load balancing based Hyper-heuristic technique with the existing Hyper-Heuristic algorithm and other heuristic algorithms based on 3 performance metrics,
- Makespan Time
- Total Processing Time”
- “Degree of Imbalance
The performance is evaluated by taking 5 different scenarios of jobs and the comparison is done based on Honey Bee optimized Hyper-Heuristic algorithm.
5.2.1 Makespan Time
In this sub-section, the performance based on the makespan time of each algorithm is evaluated and compared by changing the number of tasks. Table 5.1 shows the makespan time comparison of algorithms.
Makespan is the completion time of all the jobs in the sequence i.e the finish time of the last job in the sequence of execution.
It can be denoted in Equation 5.1”
![]()
![]()
Here the study was carried out by means of 5 distinct scenarios; the time taken from the method suggested is 30.45 milliseconds when 500 jobs have been assigned, which is 33.26 milliseconds, as shown by Table 5.1 in the Hyper-Heuristic approach. Likewise, comparisons with other heuristic algorithms such as ACO [46], PSO [61] and GA[90] have been made. The following figure 5.1 shows clearly that the suggested method is better in terms of time.
Table 5.1 Result analysis of different workflows for Makespan time
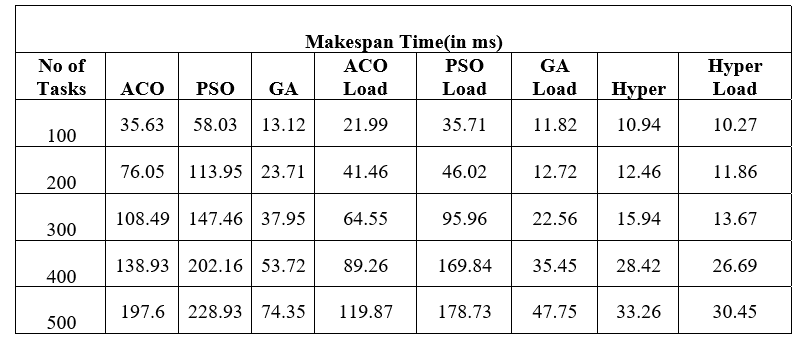
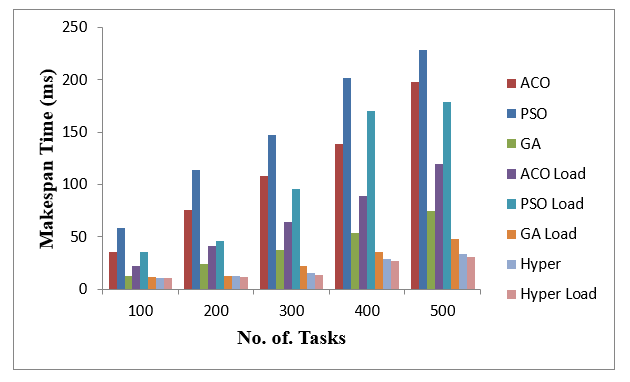
Fig 5.1 Makespan time Comparison
5.2.2 Total Processing Time
“In this sub-section, the evaluation performance of the proposed approach is calculated on the basis of Total Processing time and is matched with other existing heuristic algorithms. Table 5.2 presents processing time is one of the parameters in analyzing algorithms.
Processing Time: It is the time consumed by an algorithm to perform the given task. It is determined using the formula shown in Equation 5.2.
![]()
![]()
The processing time for the suggested method is estimated at 804.35 milliseconds for 500 jobs, which is 829.48 ms in the hyper-heuristic approach, as shown in Table 5.2. The comparison was also made with other heuristic algorithms, including ACO, PSO and GA.
Fig5.2 clearly predicts that the proposed algorithm performs better in terms of processing time metric”.
Table 5.2 Result analysis of different workflows for Total Processing Time
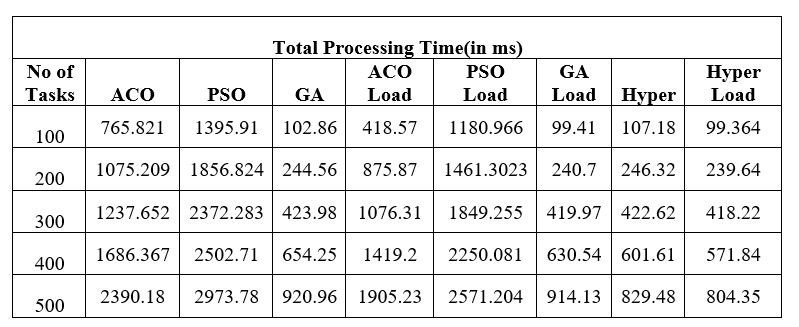

Fig 5.2 Total Processing time Comparison
5.2.3 Degree of Imbalance
“In this sub-section, the working performance of the proposed algorithm is tested on the basis of the Degree of Imbalance and is compared with another present heuristic algorithm. Table 5.3 presents a comparison of algorithms based on this imbalance factor.

In this instance, the performance was evaluated by taking a variety of tasks; the level of imbalance of the method presented was 157.64 for the 500 tasks allocated, which was 175.79 in the Hyper Heuristic approach. While our method results are not improved by fewer tasks as the number of tasks increases the degree of imbalance is improved. As shown in Table 5.3, the parameter is not improved to that much level of difference when the number of tasks is 100, 200 and 300, and when the number of tasks is over 300, it starts improving”. Figure 5.3 below demonstrates clearly that the suggested method provides improved results in the degree of imbalance measure when the number of tasks is increased.
Table 5.3 Result analysis of different workflows for degree of imbalance
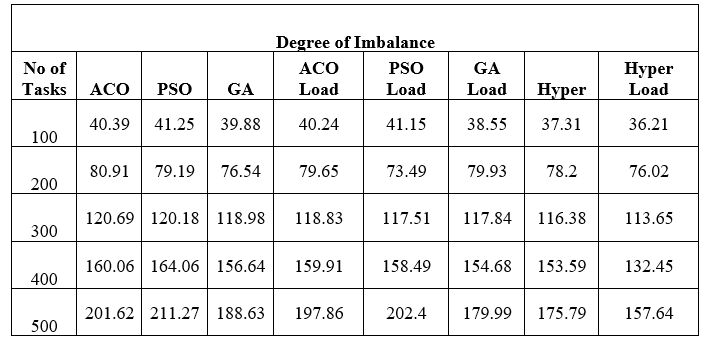
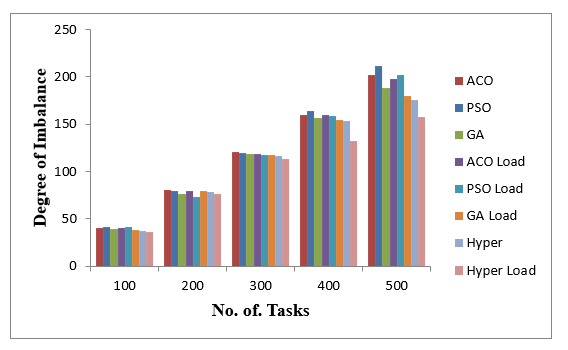
Fig 5.3 Degree of Imbalance Comparison
5.3 Efficiency Analysis of SLA-Aware Risk Management Framework(SA-RMF)
The CloudSim toolkit along with Python enabled Eclipse editor are selected as software environment’s for predicting SLAs and eliminating possible breaches.
In order to enforce SA-RMF, it is first necessary to establish a SLA between the client and the service provider.
Table 5.4 Prediction results of different methods at 5-mins interval
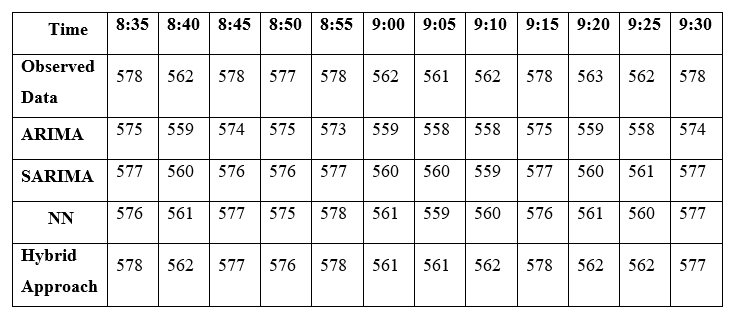
The processor is used as a SLO and tests are necessary to predetermine potential SLA violations proactively.
The first SA-RMF module is DTF, which defines the SLO threshold values. The next two phases of the SA-RMF are ORQoS and HAQoS. HAQoS employs a hybrid method for predicting the QoS values in the future.
This hybrid technique is tested with 3 existing predictive approaches known as the Automotive Regressive Integrated Moving Average (ARIMA) [75], Neural Networks (NN) and Seasonal Integrated Route Move Average (SARIMA) [25] for measuring the forecast accuracy.
To explain the process, an example is used here. Table 5.4 contains the observed and predicted QoS values from 08:35 AM to 9:30 AM.
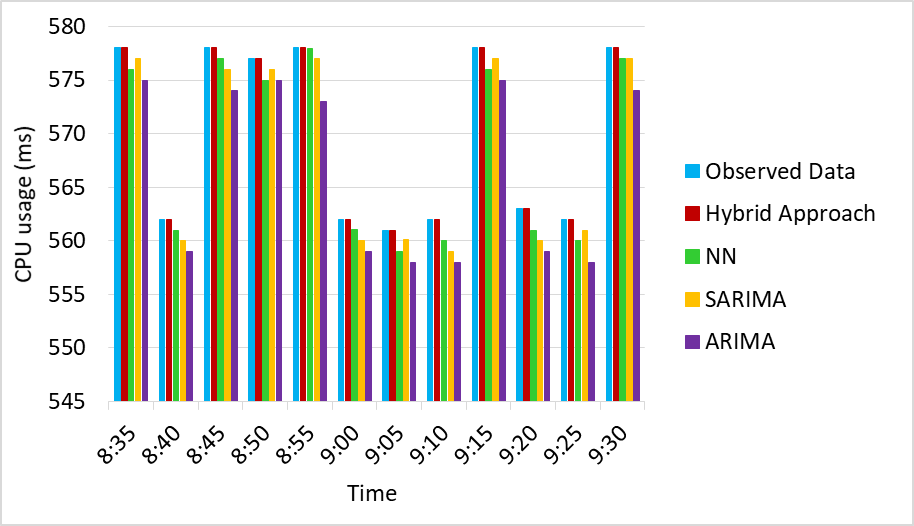
Fig 5.4 Prediction outputs of each method at 5-min intervals
“Prediction results are given at intervals of 5 min, and every unit were represented in milliseconds (ms). Fig 5.4 shows the prediction output of each method”.
Table 5.5 All methods’ accuracy in prediction
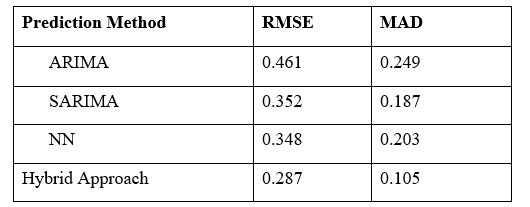
The results indicate that the anticipated Hybrid Approach QoS values are precisely in line with those observed, which implies that Hybrid Approach is very accurate. RMSE and MAD are the parameters used to measure the accuracy of all technique predictions. Equations for these two terms are denoted in Equation 5.4 and Equation 5.5.
Table 5.5 and Fig 5.5 illustrate the accuracy of all predicted precision techniques.
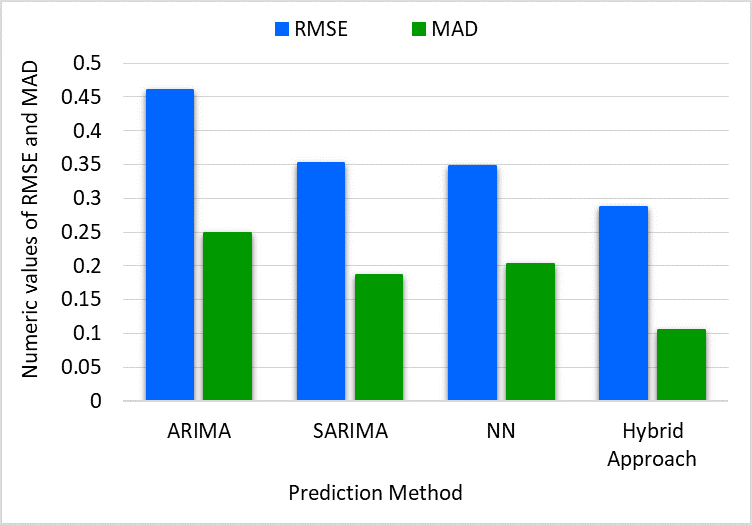
Fig 5.5 All methods accuracy in prediction using MAD and RMSE
Hybrid Approach delivers the greatest predicted outcome with a MAD value of 0.105 and RMSE value of 0.287 since it combines SARIMA, NN, and other forward multi-stage techniques as shown in Table 5.5.
Extending our example, the Hybrid Approach is used in HAQoS for predicting the QoS CPU usage period during 7:40 PM to 8:35 PM, as seen in Table 5.6.
Table 5.6 The SLO prediction over a one hour period using Hybrid Approach
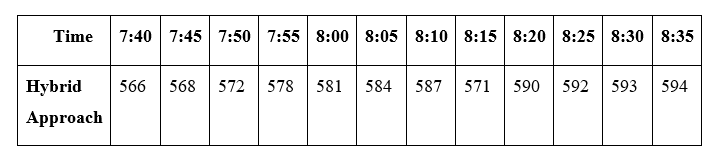
“AT is the SLO value calculated on the SLA formation which is assumed to be 600ms here, and ST is the protected threshold measurement using following equation. Let’s assume that the availability is 2296ms, the response time is 2ms and the latency is 2ms.
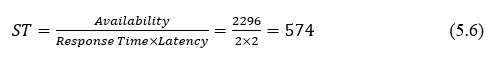
As shown in Fig 5.6, the ST and AT values are 574ms and 600ms respectively”.
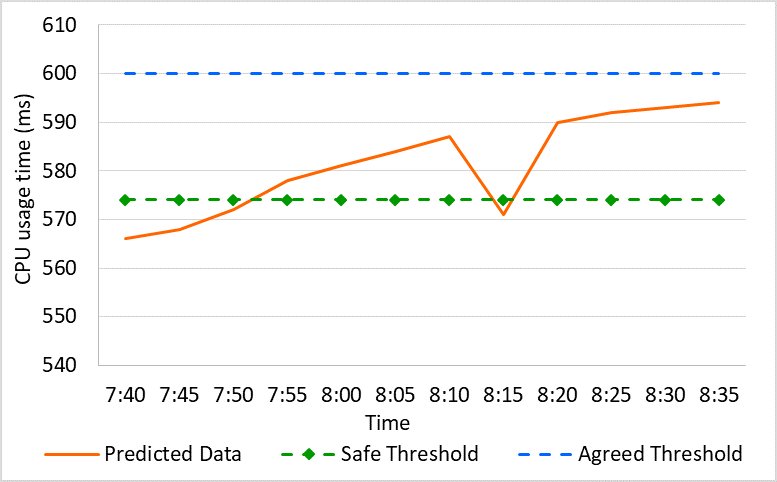
Fig 5.6 Predicted QoS values over a future time period
“The estimated QoS values are compared with these threshold values in RI module, and if the value exceeds the ST value, the RM is allowed to evaluate and manage the risk of SLA violations. The ST value is exceeded by the expected outcomes at the third interval time (7:50 PM – 7:55 PM) which is depicted in Fig 5.6”.
5.4 Summary
Honey bee based load balancing is used with Hyper-Heuristic is the first proposed work which provides better scheduling solutions. An efficient SLA-aware risk management framework (SA-RMF) for load balancing is the second proposed work. The aim of the second work is used to predict and reduce the SLA violations. The two proposed works are compared with other algorithms in this chapter by using various parameters like processing time, degree of imbalance, makespan time, prediction accuracy evaluation by RMSE and MAD.
CHAPTER-6
CONCLUSION AND FUTURE ENHANCEMENT
6.1 CONCLUSION
In this work, two major cloud problems namely task scheduling and load balancing are handled with the good effective proposed works. Additionally providing good quality of service in cloud environment with proper SLA is supported by this work.
For first problem, a Honey bee-based load balancing is used with Hyper-Heuristic algorithm is proposed which provides better scheduling solutions with reduced makespan time and processing time. With the help of the first proposed work the overloaded problem and under-loaded problem of a VM can be avoided. The proposed work provides good performance for a huge amount of allotted cloudlets in the metrics of processing cost as well as execution time of a process.
The second most important problem in cloud computing is load balancing. It is necessary to maintain a proper SLA by both provider and user to handle load balancing issues. With the help of the proposed SLA-aware risk management framework (SA-RMF) for load balancing, the SLA-violation is predicted and reduced in advance. It used machine learning based hybrid approach combining SARIMA, PCA with BAL and Neural Network techniques to predict the violation of SLA well in advance. “The SLA is managed and the SLA-violation is avoided by the service provider with the help of SA-RMF which is responsible for predicting QoS, finding potential SLA violations and to handle it. The resource allocation prediction output of NN model, ARIMA model, SARIMA model and hybrid model is obtained. From this obtained result, it is proved that this hybrid approach predict SLA violation more accurately than individual techniques”.
Finally, the efficiency of these two proposed works is analyzed by comparing with other existing approaches. The proposed Load balancing based Hyper-Heuristic approach shows good efficiency in terms of Makespan Time, Total processing time and Degree of imbalance while comparing with other techniques. The prediction accuracy was evaluated by using the MAD and RMSE values. The proposed Hybrid approach has better prediction results with good MAD and RMSE values rather than other approaches. From the performance analysis the SLA violations can be predicted earlier and it reduced with the help of the proposed hybrid model. As a result, a good quality of service is obtained by using this model.
6.2 FUTURE ENHANCEMENT
It is planned to extend our work by implementing and testing additional advanced machine learning techniques like Reinforcement Learning, Tree-RNN based solutions, or Spatio-Temporal Graph Convolutional Networks (STGCN). Also it can be extended for ranking the cloud service providers based on their performance and Key Performance Indicators to recommend the best and suitable service provider for the cloud users. ”It will benefit the end users to identify the best cloud service provider based on the user requirements.” In future the time complexity of our proposed algorithm can be improved by adjusting context-aware parameters in Cloud IoT, e.g., the maximum iteration and the weight of heuristic information.
LIST OF PUBLICATIONS
International Journal Publications
Abhishek Gupta, H.S. Bhadauria, Annapurna Singh, Load balancing based hyper heuristic algorithm for cloud task scheduling. Journal of Ambient Intelligence and Humanized Computing, 12, 5845–5852 (2021). https://doi.org/10.1007/s12652-020-02127-3 [Indexing: SCIE, Status: Published].
Abhishek Gupta, H.S. Bhadauria, Annapurna Singh, SLA-aware load balancing using risk management framework in cloud. Journal of Ambient Intelligence and Humanized Computing, 12, 7559–7568 (2021). https://doi.org/10.1007/s12652-020-02458-1 [Indexing: SCIE, Status: Published]
International Conference Publications
Abhishek Gupta, H.S. Bhadauria, Annapurna Singh, “A Theoretical Comparison of Job Scheduling Algorithms in Cloud Computing Environment”, In IEEE International Conference on Next Generation Computing Technologies(NGCT), pp. 16-20,2015
REFERENCES
- Mell, P. M., & Grance, T. (2011). The NIST definition of cloud computing. https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf
- Buyya, R., Broberg, J., & Goscinski, A. M. (2011). Cloud computing: Principles and paradigms. Wiley.
- Gibson, J., Rondeau, R., Eveleigh, D., & Tan, Q. (2012). Benefits and challenges of three cloud computing service models. 2012 Fourth International Conference on Computational Aspects of Social Networks (CASoN). https://doi.org/10.1109/cason.2012.6412402
- Singh, S. P., Kumar, R., Sharma, A., & Nayyar, A. (2020). Leveraging energy-efficient load balancing algorithms in fog computing. Concurrency and Computation: Practice and Experience. https://doi.org/10.1002/cpe.5913
- Kumar, M., Sharma, S., Goel, A., & Singh, S. (2019). A comprehensive survey for scheduling techniques in cloud computing. Journal of Network and Computer Applications, 143, 1-33. https://doi.org/10.1016/j.jnca.2019.06.006
- Kansal, N. J., & Chana, I. (2012). Cloud load balancing techniques: A step towards green computing. International Journal of Computer Science Issues (IJCSI), 9(1), 238-246.
- Arya, L. K., &Verma, A. (2014). Workflow scheduling algorithms in cloud environment – A survey. 2014 Recent Advances in Engineering and Computational Sciences (RAECS). https://doi.org/10.1109/raecs.2014.6799514
- Aladwani, T. (2020). Types of task scheduling algorithms in cloud computing environment. Scheduling Problems New Applications and Trends.
- Parsa, S., & Entezari-Maleki, R. (2009). RASA: A new task scheduling algorithm in grid environment. World Applied sciences journal, 7, 152-160.
- Ghanbari, S., & Othman, M. (2012). A Priority based Job Scheduling Algorithm in Cloud Computing. Procedia Engineering, 50, 778–785.
- Devipriya, S., & Ramesh, C. (2013). Improved Max-MIN heuristic model for task scheduling in cloud. 2013 International Conference on Green Computing, Communication and Conservation of Energy (ICGCE). https://doi.org/10.1109/icgce.2013.6823559
- Kumar, P., Gupta, J., & Gopal, K. (2013). Fault aware honey bee scheduling algorithm for cloud infrastructure. Confluence 2013: The Next Generation Information Technology Summit (4th International Conference). https://doi.org/10.1049/cp.2013.2306
- Garg, A., & Krishna, C. R. (2014). An improved honey bees life scheduling algorithm for a public cloud. 2014 International Conference on Contemporary Computing and Informatics (IC3I). https://doi.org/10.1109/ic3i.2014.7019783
- Gong, S., Yin, B., Zheng, Z., & Cai, K. (2019). Adaptive Multivariable control for multiple resource allocation of service-based systems in cloud computing. IEEE Access, 7, 13817-13831. https://doi.org/10.1109/access.2019.2894188
- Nadeem, F. (2020). A unified framework for user-preferred multi-level ranking of cloud computing services based on usability and quality of service evaluation. IEEE Access, 8, 180054-180066. https://doi.org/10.1109/access.2020.3027775
- Pang, S., Gao, Q., Liu, T., He, H., Xu, G., & Liang, K. (2019). A behavior based trustworthy service composition discovery approach in cloud environment. IEEE Access, 7, 56492-56503. https://doi.org/10.1109/access.2019.2913432
- Kong, F., Zhou, Y., Xia, B., Pan, L., & Zhu, L. (2019). A security reputation model for IoT health data using S-alexnet and dynamic game theory in cloud computing environment. IEEE Access, 7, 161822-161830. https://doi.org/10.1109/access.2019.2950731
- Liang, J., Zhang, M., & Leung, V. C. (2020). A reliable trust computing mechanism based on multisource feedback and fog computing in social sensor cloud. IEEE Internet of Things Journal, 7(6), 5481-5490. https://doi.org/10.1109/jiot.2020.2981005
- Hasan, M. M., & Mouftah, H. T. (2019). Cloud-centric collaborative security service placement for advanced metering infrastructures. IEEE Transactions on Smart Grid, 10(2), 1339-1348. https://doi.org/10.1109/tsg.2017.2763954
- Xu, J., Liang, C., Jain, H. K., & Gu, D. (2019). Openness and security in cloud computing services: Assessment methods and investment strategies analysis. IEEE Access, 7, 29038-29050. https://doi.org/10.1109/access.2019.2900889
- Son, J., & Buyya, R. (2019). Priority-aware VM allocation and network bandwidth provisioning in software-defined networking (sdn)-enabled clouds. IEEE Transactions on Sustainable Computing, 4(1), 17-28. https://doi.org/10.1109/tsusc.2018.2842074
- Li, X., Wang, Q., Lan, X., Chen, X., Zhang, N., & Chen, D. (2019). Enhancing cloud-based IoT security through trustworthy cloud service: An integration of security and reputation approach. IEEE Access, 7, 9368-9383. https://doi.org/10.1109/access.2018.2890432
- Dbouk, T., Mourad, A., Otrok, H., Tout, H., & Talhi, C. (2019). A novel ad-hoc mobile edge cloud offering security services through intelligent resource-aware offloading. IEEE Transactions on Network and Service Management, 16(4), 1665-1680.
- Guan, S., De Grande, R. E., & Boukerche, A. (2019). A multi-layered scheme for distributed simulations on the cloud environment. IEEE Transactions on Cloud Computing, 7(1), 5-18. https://doi.org/10.1109/tcc.2015.2453945
- Alencar, D. B., Affonso, C. M., Oliveira, R. C., & Filho, J. C. (2018). Hybrid approach combining SARIMA and neural networks for multi-step ahead wind speed forecasting in Brazil. IEEE Access, 6, 55986-55994. https://doi.org/10.1109/access.2018.2872720
- Godfrey, L. B., & Gashler, M. S. (2017). Neural decomposition of time-series data for effective generalization. IEEE Transactions on Neural Networks and Learning Systems, 1-13. https://doi.org/10.1109/tnnls.2017.2709324
- Hieu, N. T., Francesco, M. D., & Yla-Jaaski, A. (2020). Virtual machine consolidation with multiple usage prediction for energy-efficient cloud data centers. IEEE Transactions on Services Computing, 13(1), 186-199. https://doi.org/10.1109/tsc.2017.2648791
- Melhem, S. B., Agarwal, A., Goel, N., & Zaman, M. (2018). Markov prediction model for host load detection and VM placement in live migration. IEEE Access, 6, 7190-7205. https://doi.org/10.1109/access.2017.2785280
- Liu, F., Ma, Z., Wang, B., & Lin, W. (2019). A virtual machine consolidation algorithm based on ant colony system and extreme learning machine for cloud data center. IEEE Access, 8, 53-67. https://doi.org/10.1109/access.2019.2961786
- Liaqat, M., Naveed, A., Ali, R. L., Shuja, J., & Ko, K. (2019). Characterizing dynamic load balancing in cloud environments using virtual machine deployment models. IEEE Access, 7, 145767-145776. https://doi.org/10.1109/access.2019.2945499
- Jin, X., Wang, Q., Li, X., Chen, X., & Wang, W. (2019). Cloud virtual machine lifecycle security framework based on trusted computing. Tsinghua Science and Technology, 24(5), 520-534. https://doi.org/10.26599/tst.2018.9010129
- Li, L., Dong, J., Zuo, D., & Wu, J. (2019). SLA-aware and energy-efficient VM consolidation in cloud data centers using robust linear regression prediction model. IEEE Access, 7, 9490-9500. https://doi.org/10.1109/access.2019.2891567
- Meneguette, R. I., & Boukerche, A. (2019). An efficient green-aware architecture for virtual machine migration in sustainable vehicular clouds. IEEE Transactions on Sustainable Computing, 5(1), 25-36. https://doi.org/10.1109/tsusc.2019.2904672
- Liu, S., Li, C., Liu, Z., & Zhang, Q. (2020). Virtual machine dynamic deployment scheme based on double-cursor mechanism. IEEE Access, 8, 214481-214493.
- Sharma, N. K., & Reddy, G. R. (2019). Multi-objective energy efficient virtual machines allocation at the cloud data center. IEEE Transactions on Services Computing, 12(1), 158-171. https://doi.org/10.1109/tsc.2016.2596289
- Hussain, W., & Sohaib, O. (2019). Analysing cloud QoS prediction approaches and its control parameters: Considering overall accuracy and freshness of a dataset. IEEE Access, 7, 82649-82671. https://doi.org/10.1109/access.2019.2923706
- Kim, C., Choi, S., & Huh, J. (2019). GVTS: Global virtual time fair scheduling to support strict fairness on many cores. IEEE Transactions on Parallel and Distributed Systems, 30(1), 79-92. https://doi.org/10.1109/tpds.2018.2851515
- Kamiyama, N. (2019). Virtual machine trading in public clouds. IEEE Transactions on Network and Service Management,17(1), 403-415. https://doi.org/10.1109/tnsm.2019.2946217
- Sotiriadis, S., Bessis, N., Amza, C., & Buyya, R. (2019). Elastic load balancing for dynamic virtual machine reconfiguration based on vertical and horizontal scaling. IEEE Transactions on Services Computing, 12(2), 319-334. https://doi.org/10.1109/tsc.2016.2634024
- Tang, F., Yang, L. T., Tang, C., Li, J., & Guo, M. (2018). A dynamical and load-balanced flow scheduling approach for big data centers in clouds. IEEE Transactions on Cloud Computing, 6(4), 915-928. https://doi.org/10.1109/tcc.2016.2543722
- Hussain, A., Aleem, M., Khan, A., Iqbal, M. A., & Islam, M. A. (2018). RALBA: A computation-aware load balancing scheduler for cloud computing. Cluster Computing, 21(3), 1667-1680. https://doi.org/10.1007/s10586-018-2414-6
- Kumar, P., & Kumar, R. (2019). Issues and challenges of load balancing techniques in cloud computing. ACM Computing Surveys, 51(6), 1-35. https://doi.org/10.1145/3281010
- Ala’Anzy, M., & Othman, M. (2019). Load balancing and server consolidation in cloud computing environments: A meta-study. IEEE Access, 7, 141868-141887.
- Goswami, N., Garala, K., & Maheta, P. (2015). Cloud Load Balancing Based on Ant Colony Optimization Algorithm. IOSR Journal of Computer Engineering (IOSR-JCE), 1(1), 11-18. https://doi.org/ 10.13140/RG.2.1.4914.8001
- Dey, N. S., & Gunasekhar, T. (2019). A comprehensive survey of load balancing strategies using Hadoop queue scheduling and virtual machine migration. IEEE Access, 7, 92259-92284. https://doi.org/10.1109/access.2019.2927076
- Tsai, C., Huang, W., Chiang, M., Chiang, M., & Yang, C. (2014). A hyper-heuristic scheduling algorithm for cloud. IEEE Transactions on Cloud Computing, 2(2), 236-250. https://doi.org/10.1109/tcc.2014.2315797
- Tawfeek, M. A., El-Sisi, A., Keshk, A. E., & Torkey, F. A. (2013). Cloud task scheduling based on ant colony optimization. 2013 8th International Conference on Computer Engineering & Systems (ICCES). https://doi.org/10.1109/icces.2013.6707172
- Zhan, Z., Zhang, G., Ying-Lin, Gong, Y., & Zhang, J. (2014). Load balance aware genetic algorithm for task scheduling in cloud computing. Lecture Notes in Computer Science, 644-655. https://doi.org/10.1007/978-3-319-13563-2_54
- Liu, Z., & Wang, X. (2012). A PSO-based algorithm for load balancing in virtual machines of cloud computing environment. Lecture Notes in Computer Science, 142-147. https://doi.org/10.1007/978-3-642-30976-2_17
- Elhady, G. F., & Tawfeek, M. A. (2015). A comparative study into swarm intelligence algorithms for dynamic tasks scheduling in cloud computing. 2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS). https://doi.org/10.1109/intelcis.2015.7397246
- Rajput, S. S., & Kushwah, V. S. (2016). A genetic based improved load balanced MIN-MIN task scheduling algorithm for load balancing in cloud computing. 2016 8th International Conference on Computational Intelligence and Communication Networks (CICN). https://doi.org/10.1109/cicn.2016.139
- Selvarani, S., & Sadhasivam, G. S. (2010). Improved cost-based algorithm for task scheduling in cloud computing. 2010 IEEE International Conference on Computational Intelligence and Computing Research. https://doi.org/10.1109/iccic.2010.5705847
- Fakhfakh, F., Kacem, H. H., & Kacem, A. H. (2014). Workflow scheduling in cloud computing: A survey. 2014 IEEE 18th International Enterprise Distributed Object Computing Conference Workshops and Demonstrations.
- Li, K., Xu, G., Zhao, G., Dong, Y., & Wang, D. (2011). Cloud task scheduling based on load balancing ant colony optimization. 2011 Sixth Annual Chinagrid Conference. https://doi.org/10.1109/chinagrid.2011.17
- Zuo, L., Shu, L., Dong, S., Zhu, C., & Hara, T. (2015). A Multi-Objective Optimization Scheduling Method Based on the Ant Colony Algorithm in Cloud Computing. Proceedings of the IEEE Conference on Access Big Data Services and Computational Intelligence for Industrial Systems. https://doi.org/ 10.1109/ACCESS.2015.2508940
- Kumar, P., & Verma, A. (2012). Scheduling using improved genetic algorithm in cloud computing for independent tasks. Proceedings of the International Conference on Advances in Computing, Communications and Informatics – ICACCI ’12.
- Zhang, H. (2015). Research on job security scheduling strategy in cloud computing model. 2015 International Conference on Intelligent Transportation, Big Data and Smart City. https://doi.org/10.1109/icitbs.2015.165
- Chiang, M., Hsieh, H., Tsai, W., & Ke, M. (2017). An improved task scheduling and load balancing algorithm under the heterogeneous cloud computing network. 2017 IEEE 8th International Conference on Awareness Science and Technology (iCAST).
- Zhang, Y., & Yang, R. (2017). Cloud computing task scheduling based on improved particle swarm optimization algorithm. IECON 2017 – 43rd Annual Conference of the IEEE Industrial Electronics Society. https://doi.org/10.1109/iecon.2017.8217541
- Zhang, H., Li, P., Zhou, Z., & Yu, X. (2013). A PSO-based hierarchical resource scheduling strategy on cloud computing. Trustworthy Computing and Services, 325-332. https://doi.org/10.1007/978-3-642-35795-4_41
- Al-Olimat, H. S., Alam, M., Green, R., & Lee, J. K. (2015). Cloudlet scheduling with particle swarm optimization. 2015 Fifth International Conference on Communication Systems and Network Technologies. https://doi.org/10.1109/csnt.2015.252
- Kimpan, W., & Kruekaew, B. (2016). Heuristic task scheduling with artificial bee colony algorithm for virtual machines. 2016 Joint 8th International Conference on Soft Computing and Intelligent Systems (SCIS) and 17th International Symposium on Advanced Intelligent Systems (ISIS). https://doi.org/10.1109/scis-isis.2016.0067
- Nhlabatsi, A., Hong, J. B., Kim, D. S., Fernandez, R., Hussein, A., Fetais, N., & Khan, K. M. (2018). Threat-specific security risk evaluation in the cloud. IEEE Transactions on Cloud Computing, 9(2), 793-806. https://doi.org/10.1109/tcc.2018.2883063
- Carvalho, G. H., Woungang, I., Anpalagan, A., & Traore, I. (2021). Optimal security risk management mechanism for the 5G Cloudified infrastructure. IEEE Transactions on Network and Service Management, 18(2), 1260-1274. https://doi.org/10.1109/tnsm.2021.3057761
- Djemame, K., Armstrong, D., Guitart, J., & Macias, M. (2016). A risk assessment framework for cloud computing. IEEE Transactions on Cloud Computing, 4(3), 265-278. https://doi.org/10.1109/tcc.2014.2344653
- Han, S., Han, K., & Zhang, S. (2019). A data sharing protocol to minimize security and privacy risks of cloud storage in big data era. IEEE Access, 7, 60290-60298. https://doi.org/10.1109/access.2019.2914862
- Wang, M., Xu, C., Chen, X., Zhong, L., Wu, Z., & Wu, D. O. (2021). BC-mobile device cloud: A blockchain-based decentralized truthful framework for mobile device cloud. IEEE Transactions on Industrial Informatics, 17(2), 1208-1219.
- Bai, Y., Chen, L., Song, L., & Xu, J. (2020). Risk-aware edge computation offloading using Bayesian Stackelberg game. IEEE Transactions on Network and Service Management, 17(2), 1000-1012. https://doi.org/10.1109/tnsm.2020.2985080
- Youssef, A. E. (2019). A framework for cloud security risk management based on the business objectives of organizations. International Journal of Advanced Computer Science and Applications, 10(12). https://doi.org/10.14569/ijacsa.2019.0101226
- Singh, S., Chana, I., & Buyya, R. (2017). STAR: SLA-aware autonomic management of cloud resources. IEEE Transactions on Cloud Computing, 8(4), 1040-1053. https://doi.org/10.1109/tcc.2017.2648788
- Yao, M., Chen, D., & Shang, J. (2019). Optimal overbooking policy for cloud service providers: Profit and service quality. IEEE Access, 7, 96132-96147.
- Yadav, R., Zhang, W., Kaiwartya, O., Singh, P. R., Elgendy, I. A., & Tian, Y. (2018). Adaptive energy-aware algorithms for minimizing energy consumption and SLA violation in cloud computing. IEEE Access, 6, 55923-55936.
- Zhou, Z., Hu, Z., & Li, K. (2016). Virtual machine placement algorithm for both energy-awareness and SLA violation reduction in cloud data centers. Scientific Programming, 2016, 1-11. https://doi.org/10.1155/2016/5612039
- Ammar, A., Luo, J., Tang, Z., & Wajdy, O. (2019). Intra-balance virtual machine placement for effective reduction in energy consumption and SLA violation. IEEE Access, 7, 72387-72402. https://doi.org/10.1109/access.2019.2920010
- Hussain, W., Hussain, F. K., Hussain, O., Bagia, R., & Chang, E. (2018). Risk-based framework for SLA violation abatement from the cloud service provider’s perspective. The Computer Journal, 61(9), 1306-1322. https://doi.org/10.1093/comjnl/bxx118
- Alsarhan, A., Itradat, A., Al-Dubai, A. Y., Zomaya, A. Y., & Min, G. (2018). Adaptive resource allocation and provisioning in multi-service cloud environments. IEEE Transactions on Parallel and Distributed Systems, 29(1), 31-42.
- Mustafa, S., Sattar, K., Shuja, J., Sarwar, S., Maqsood, T., Madani, S. A., & Guizani, S. (2019). SLA-aware best fit decreasing techniques for workload consolidation in clouds. IEEE Access, 7, 135256-135267. https://doi.org/10.1109/access.2019.2941145
- Hussain, W., Hussain, F. K., & Hussain, O. K. (2016). Risk management framework to avoid SLA violation in cloud from a provider’s perspective. Advances on P2P, Parallel, Grid, Cloud and Internet Computing, 233-241. https://doi.org/10.1007/978-3-319-49109-7_22
- Haratian, P., Safi-Esfahani, F., Salimian, L., & Nabiollahi, A. (2019). An adaptive and fuzzy resource management approach in cloud computing. IEEE Transactions on Cloud Computing, 7(4), 907-920. https://doi.org/10.1109/tcc.2017.2735406
- Paputungan, I. V., Hani, A. F., Hassan, M. F., & Asirvadam, V. S. (2019). Real-time and proactive SLA renegotiation for a cloud-based system. IEEE Systems Journal, 13(1), 400-411. https://doi.org/10.1109/jsyst.2018.2805293
- Xiao, H., Hu, Z., & Li, K. (2019). Multi-objective VM consolidation based on thresholds and ant colony system in cloud computing. IEEE Access, 7, 53441-53453.
- Ali, Z., Khaf, S., Abbas, Z. H., Abbas, G., Muhammad, F., & Kim, S. (2020). A deep learning approach for mobility-aware and energy-efficient resource allocation in MEC. IEEE Access, 8, 179530-179546. https://doi.org/10.1109/access.2020.3028240
- Guo, W., Tian, W., Ye, Y., Xu, L., & Wu, K. (2021). Cloud resource scheduling with deep reinforcement learning and imitation learning.IEEE Internet of Things Journal, 8(5), 3576-3586.https://doi.org/10.1109/jiot.2020.3025015
- Lin, J., Cui, D., Peng, Z., Li, Q., & He, J. (2020). A two-stage framework for the multi-user multi-data center job scheduling and resource allocation. IEEE Access, 8, 197863-197874. https://doi.org/10.1109/access.2020.3033557
- Alfakih, T., Hassan, M. M., Gumaei, A., Savaglio, C., & Fortino, G. (2020). Task offloading and resource allocation for mobile edge computing by deep reinforcement learning based on SARSA. IEEE Access, 8, 54074-54084. https://doi.org/10.1109/access.2020.2981434
- Merluzzi, M., Lorenzo, P. D., & Barbarossa, S. (2021). Wireless edge machine learning: Resource allocation and trade-offs. IEEE Access, 9, 45377-45398.
- Zou, J., Hao, T., Yu, C., & Jin, H. (2021). A3C-DO: A regional resource scheduling framework based on deep reinforcement learning in edge scenario. IEEE Transactions on Computers, 70(2), 228-239. https://doi.org/10.1109/tc.2020.2987567
- Cui, Y., Huang, X., Wu, D., & Zheng, H. (2020). Machine learning-based resource allocation strategy for network slicing in vehicular networks. Wireless Communications and Mobile Computing, 2020, 1-10. https://doi.org/10.1155/2020/8836315
- Yang, J., & Chen, Z. (2010). Cloud computing research and security issues. 2010 International Conference on Computational Intelligence and Software Engineering. https://doi.org/10.1109/cise.2010.5677076
- Agarwal, M., & Srivastava, G. M. (2016). A genetic algorithm inspired task scheduling in cloud computing. 2016 International Conference on Computing, Communication and Automation (ICCCA). https://doi.org/10.1109/ccaa.2016.7813746
- D., D. B., & Venkata Krishna, P. (2013). Honey bee behavior inspired load balancing of tasks in cloud computing environments. Applied Soft Computing, 13(5), 2292-2303. https://doi.org/10.1016/j.asoc.2013.01.025
- Sutha, K., & Nawaz, G. M. (2017). Research perspective of job scheduling in cloud computing. 2016 Eighth International Conference on Advanced Computing (ICoAC). https://doi.org/10.1109/icoac.2017.7951746
- Goiri, Í.,Julià, F., Fitó, J. O., Macías, M., & Guitart, J. (2012). Supporting CPU-based guarantees in cloud SLAs via resource-level QoS metrics. Future Generation Computer Systems, 28(8), 1295–1302. doi:10.1016/j.future.2011.11.004
- Ni, W., Zhang, Y., & Li, W. W. (2019). An optimal strategy for resource utilization in cloud data centers. IEEE Access, 7, 158095-158112. https://doi.org/10.1109/access.2019.2950435
- Shelja Jose M, 2015, Optimal Resource Provisioning in Cloud Computing, International Journal of Engineering Research & Technology (IJERT) NSDMCC – 2015 (Volume 4 – Issue 06).
- Zayegh, A., & Al Bassam, N. (2018). Neural network principles and applications. Digital Systems. https://doi.org/10.5772/intechopen.80416
- Rakesh Kumar, Y., Abhishek, M., Navin, P., &Himanshu, S. (2010). An Improved Round Robin Scheduling Algorithm for CPU scheduling. International Journal on Computer Science and Engineering (IJCSE), 2(4), 1064-1066.
- Malgari, V., Dugyala, R., & Kumar, A. (2019). A novel data security framework in distributed cloud computing. 2019 Fifth International Conference on Image Information Processing (ICIIP). https://doi.org/10.1109/iciip47207.2019.8985941
- Ajmera, K., & Kumar Tewari, T. (2018). Greening the cloud through power-aware virtual machine allocation. 2018 Eleventh International Conference on Contemporary Computing (IC3). https://doi.org/10.1109/ic3.2018.8530625
- Singh, R., Gupta, P. K., Gupta, P., Malekian, R., Maharaj, B. T., Andriukaitis, D., Valinevicius, A., Bogatinoska, D. C., & Karadimce, A. (2015). Load balancing of distributed servers in distributed file systems. ICT Innovations 2015, 29-37. https://doi.org/10.1007/978-3-319-25733-4_4
- Kumar, N., & Singh, Y. (2017). Trust and packet load balancing based secure opportunistic routing protocol for WSN. 2017 4th International Conference on Signal Processing, Computing and Control (ISPCC). https://doi.org/10.1109/ispcc.2017.8269723
- Sourav, D., & Vijay Kumar, J. (2014). Classification Based Novel Framework for Network Traffic Analysis in Cloud Computing. International Journal of Computer Engineering and Applications, 6(3).
- Sachin, S., Rahul Kumar, M., & Mayank, A. (2018). A comparative study on scheduling Algorithms in cloud computing. International Journal of Advanced Research in Computer Engineering & Technology (IJARCET), 7(1).
- Kumari, S., &Ojha, A. (2014). Maintainable stochastic flow networks with high QoS: A quick and practical approach. 2014 Fourth International Conference on Advances in Computing and Communications. https://doi.org/10.1109/icacc.2014.69
- Divyashree, H. B., Puttamadappa, C., & Nandini Prasad, K. S. (2020). Performance analysis and enhancement of QoS parameters for real-time applications in MANETs-comparative study. 2020 International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT).
- Kuang, Y., Singh, R., Singh, S., & Singh, S. P. (2017). A novel macroeconomic forecasting model based on revised multimedia assisted BP neural network model and ant colony algorithm. Multimedia Tools and Applications, 76(18), 18749-18770. https://doi.org/10.1007/s11042-016-4319-9
- Meenakshi, S., & Puneet, B. (2017). Efficacy of artificial neural network for financial literacy prediction. International Journal of Advanced Research in IT and Engineering, 6(2).
- Wu, C., Chang, R., & Chan, H. (2014). A green energy-efficient scheduling algorithm using the DVFS technique for cloud datacenters. Future Generation Computer Systems, 37, 141-147. https://doi.org/10.1016/j.future.2013.06.009
- Mansouri, N., Mohammad Hasani Zade, B., & Javidi, M. M. (2019). Hybrid task scheduling strategy for cloud computing by modified particle swarm optimization and fuzzy theory. Computers & Industrial Engineering, 130, 597-633.
- Ben Alla, H., Ben Alla, S., Touhafi, A., & Ezzati, A. (2018). A novel task scheduling approach based on dynamic queues and hybrid meta-heuristic algorithms for cloud computing environment. Cluster Computing, 21(4), 1797-1820.
- Remesh Babu, K. R., Joy, A. A., & Samuel, P. (2015). Load balancing of tasks in cloud computing environment based on bee colony algorithm. 2015 Fifth International Conference on Advances in Computing and Communications (ICACC
- Jafarnejad Ghomi, E., Masoud Rahmani, A., & Nasih Qader, N. (2017). Load-balancing algorithms in cloud computing: A survey. Journal of Network and Computer Applications, 88, 50-71. https://doi.org/10.1016/j.jnca.2017.04.007
- Attaran, M., & Deb, P. (2018). Machine learning: The new ‘big thing’ for competitive advantage. International Journal of Knowledge Engineering and Data Mining, 5(4), 277. https://doi.org/10.1504/ijkedm.2018.095523
- Paya, A., & Marinescu, D. C. (2017). Energy-aware load balancing and application scaling for the cloud ecosystem. IEEE Transactions on Cloud Computing, 5(1), 15-27. https://doi.org/10.1109/tcc.2015.2396059
- Liu, Q., Cai, W., Shen, J., Liu, X., & Linge, N. (2016). An adaptive approach to better load balancing in a consumer-centric cloud environment. IEEE Transactions on Consumer Electronics, 62(3), 243-250. https://doi.org/10.1109/tce.2016.7613190
- Deng, R., Lu, R., Lai, C., Luan, T. H., & Liang, H. (2016). Optimal workload allocation in fog-cloud computing towards balanced delay and power consumption. IEEE Internet of Things Journal, 1-1. https://doi.org/10.1109/jiot.2016.2565516
- Luo, J., Rao, L., & Liu, X. (2015). Spatio-temporal load balancing for energy cost optimization in distributed internet data centers. IEEE Transactions on Cloud Computing, 3(3), 387-397. https://doi.org/10.1109/tcc.2015.2415798
- Montazerolghaem, A., Yaghmaee, M. H., Leon-Garcia, A., Naghibzadeh, M., &Tashtarian, F. (2016). A load-balanced call admission controller for IMS cloud computing. IEEE Transactions on Network and Service Management, 13(4), 806-822. https://doi.org/10.1109/tnsm.2016.2572161
- Hongbin Liang, Cai, L. X., Dijiang Huang, XueminShen, & DaiyuanPeng. (2012). An SMDP-based service model for Interdomain resource allocation in mobile cloud networks. IEEE Transactions on Vehicular Technology, 61(5), 2222-2232. https://doi.org/10.1109/tvt.2012.2194748
- Xu, F., Liu, F., Liu, L., Jin, H., Li, B., & Li, B. (2014). IAware: Making live migration of virtual machines interference-aware in the cloud. IEEE Transactions on Computers, 63(12), 3012-3025. https://doi.org/10.1109/tc.2013.185
- Duan, J., & Yang, Y. (2017). A load balancing and multi-tenancy oriented data center virtualization framework. IEEE Transactions on Parallel and Distributed Systems, 28(8), 2131-2144. https://doi.org/10.1109/tpds.2017.2657633
- Nguyen, K. K., & Cheriet, M. (2015). Environment-aware virtual Slice provisioning in green cloud environment. IEEE Transactions on Services Computing, 8(3), 507-519. https://doi.org/10.1109/tsc.2014.2362544
- Wood, T., Ramakrishnan, K. K., Shenoy, P., Van der Merwe, J., Hwang, J., Liu, G., & Chaufournier, L. (2015). CloudNet: Dynamic pooling of cloud resources by live WAN migration of virtual machines. IEEE/ACM Transactions on Networking, 23(5), 1568-1583. https://doi.org/10.1109/tnet.2014.2343945
- Beloglazov, A., & Buyya, R. (2013). Managing overloaded hosts for dynamic consolidation of virtual machines in cloud data centers under quality of service constraints. IEEE Transactions on Parallel and Distributed Systems, 24(7), 1366-1379. https://doi.org/10.1109/tpds.2012.240
- Xiangping Bu, JiaRao, & Cheng-ZhongXu. (2013). Coordinated self-configuration of virtual machines and appliances using a model-free learning approach. IEEE Transactions on Parallel and Distributed Systems, 24(4), 681-690. https://doi.org/10.1109/tpds.2012.174
- Rodriguez, M. A., & Buyya, R. (2014). Deadline based resource Provisioningand scheduling algorithm for scientific workflows on clouds. IEEE Transactions on Cloud Computing, 2(2), 222-235. https://doi.org/10.1109/tcc.2014.2314655
- Zhu, X., Yang, L. T., Chen, H., Wang, J., Yin, S., & Liu, X. (2014). Real-time tasks oriented energy-aware scheduling in Virtualized clouds. IEEE Transactions on Cloud Computing, 2(2), 168-180. https://doi.org/10.1109/tcc.2014.2310452
- Wu, S., Chen, H., Di, S., Zhou, B., Xie, Z., Jin, H., & Shi, X. (2015). Synchronization-aware scheduling for virtual clusters in cloud. IEEE Transactions on Parallel and Distributed Systems, 26(10), 2890-2902. https://doi.org/10.1109/tpds.2014.2359017
- Zhang, Q., Zhani, M. F., Yang, Y., Boutaba, R., & Wong, B. (2015). PRISM: Fine-grained resource-aware scheduling for MapReduce. IEEE Transactions on Cloud Computing, 3(2), 182-194. https://doi.org/10.1109/tcc.2014.2379096
- Ferdousi, S., Dikbiyik, F., FarhanHabib, M., Tornatore, M., & Mukherjee, B. (2015). Disaster-aware Datacenter placement and dynamic content management in cloud networks. Journal of Optical Communications and Networking, 7(7), 681.
- Sharma, B., Thulasiram, R. K., Thulasiraman, P., & Buyya, R. (2015). Clabacus: A risk-adjusted cloud resources pricing model using financial option theory. IEEE Transactions on Cloud Computing, 3(3), 332-344. https://doi.org/10.1109/tcc.2014.2382099
- Zhang, Q., Li, S., Li, Z., Xing, Y., Yang, Z., & Dai, Y. (2015). CHARM: A cost-efficient multi-cloud data hosting scheme with high availability. IEEE Transactions on Cloud Computing, 3(3), 372-386. https://doi.org/10.1109/tcc.2015.2417534
- Wang, J., Bao, W., Zhu, X., Yang, L. T., & Xiang, Y. (2015). FESTAL: Fault-tolerant elastic scheduling algorithm for real-time tasks in Virtualized clouds. IEEE Transactions on Computers, 64(9), 2545-2558. https://doi.org/10.1109/tc.2014.2366751
- Zhang, C., Yao, J., Qi, Z., Yu, M., & Guan, H. (2014). VGASA: Adaptive scheduling algorithm of Virtualized GPU resource in cloud gaming. IEEE Transactions on Parallel and Distributed Systems, 25(11), 3036-3045. https://doi.org/10.1109/tpds.2013.288
- Calheiros, R. N., Ranjan, R., Beloglazov, A., De Rose, C. A., & Buyya, R. (2010). CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Software: Practice and Experience, 41(1), 23-50. https://doi.org/10.1002/spe.995